Preface
Goal: Reading a predefined sheet to a plain dataframe, and build sheet in the same workbook.
In real-world scenarios, the data sources we encounter might vary. While one might expect a clean CSV as input, others may prefer providing information in the form of a sheet. In this context, we require a dataframe that reads from a table sheet and subsequently generates a pivot sheet within the same workbook.
Reader: Main Script
To illustrate the process,
we will utilize our existing Example.xlsx workbook
and read data from the Table worksheet.
Source
This is the source worksheet that we want to read.
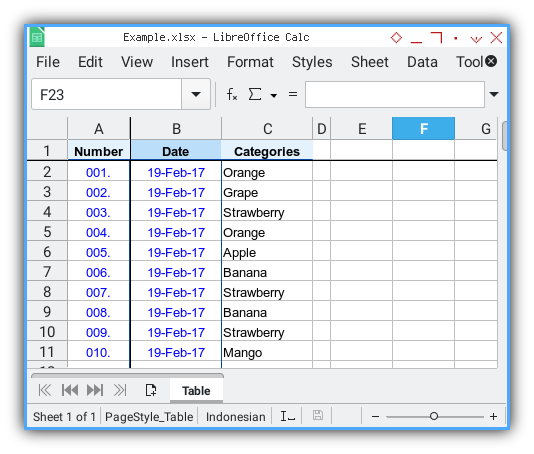
The source worksheet, features a plain table with three columns: A, B, C.
Class Diagram
The class diagram closely resembles that of the CSV reader, providing a streamlined approach.
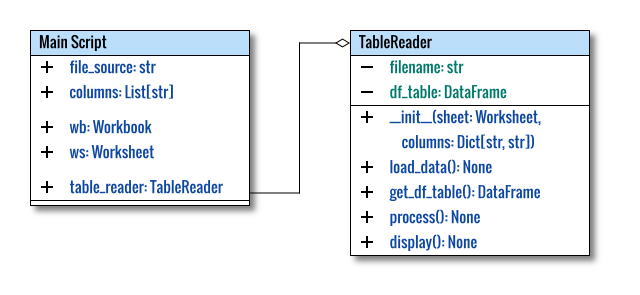
Local Libraries
Just
TableReader.
Don’t worry. This is a short class.
# openPyXL
from openpyxl import Workbook, load_workbook
# Local Library
from lib.TableReader import TableReader
Utilizing only TableReader. Rest assured, this class is concise and straightforward.
Directory Structure
The directory structure reflects a well-organized arrangement, as shown below:
.
├── 17-reader.py
└── lib
└── TableReader.pyMain Method
The initial section defines custom variables, and categories serving as inputs for class initialization.
def main() -> None:
file_source = 'Example.xlsx'
columns = {
'index' : 'A',
'date' : 'B',
'cat' : 'C'
}
wb = load_workbook(file_source)
ws = wb['Table']
table_reader = TableReader(ws, columns)
table_reader.process()
table_reader.display()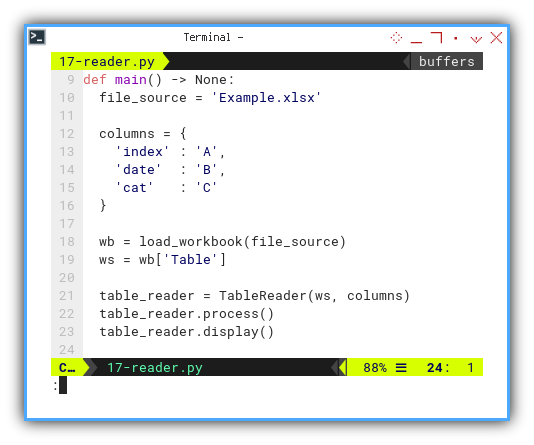
We have explicitly specified the columns to be used: A, B, C.
Table Reader Class
This script essentially comprises a loop, that iterates over a range of rows in a worksheet, concatenating the values into a dataframe.
With the ability to read and write to worksheets, basic macro skills are sufficient for straightforward data processing, providing room for playful exploration of substantial worksheet data.
Library
import pandas as pd
from typing import Dict
from pandas import DataFrame
# openPyXL
from openpyxl.worksheet.worksheet import Worksheet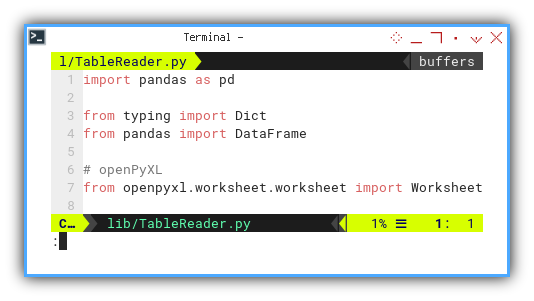
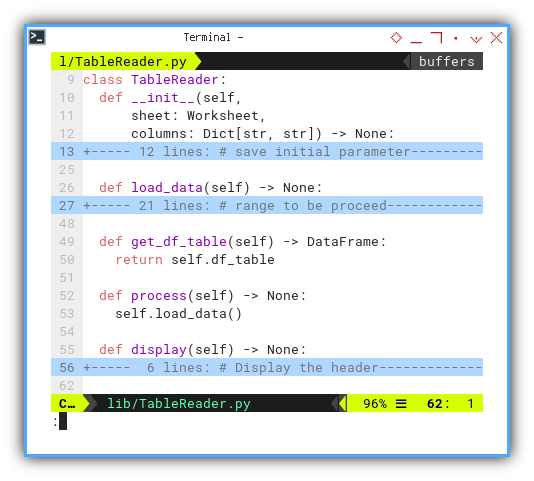
Class Skeleton
The class skeleton is outlined below:
class TableReader:
def __init__(self,
sheet: Worksheet,
columns: Dict[str, str]) -> None:
...
def load_data(self) -> None:
...
def get_df_table(self) -> DataFrame:
return self.df_table
def process(self) -> None:
self.load_data()
def display(self) -> None:
...
Initialization
Two parameters are expected here:
- The first: denotes the data source.
- The second: specifies the columns to map the data.
def __init__(self,
sheet: Worksheet,
columns: Dict[str, str]) -> None:
# save initial parameter
self.sheet = sheetWe can efficiently unpack the mapping columns to self as usual.
# Unpack the dictionary keys and values
# into class attributes
for key, value in columns.items():
setattr(self, f"col_{key}", value)And also initialize dataframe.
# initialize dataframe
self.df_table = pd.DataFrame({
"Number": [], "Date": [], "Category": [] })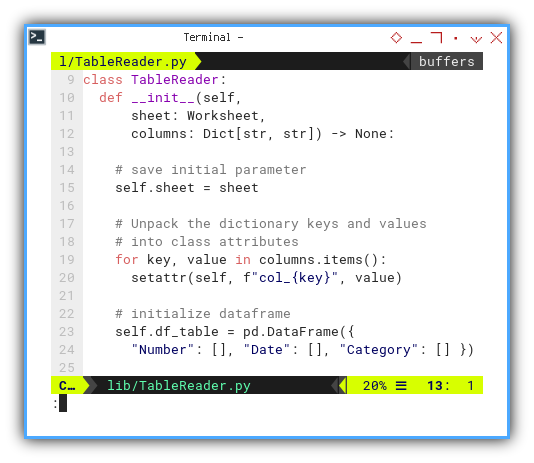
Now, the dataframe can be utilized based on the predefined list above.
Loading Data
Fortuitously, openPyXL introduces a convenient max_row feature,
negating the need for manual determination of table length.
Now we can establish a predefined range as the basis for our loop.
def load_data(self) -> None:
# range to be proceed
# omit header and plus one for the last
max_row = self.sheet.max_row
range_rows = range(2, max_row+1)
print(f'Range : {range_rows}')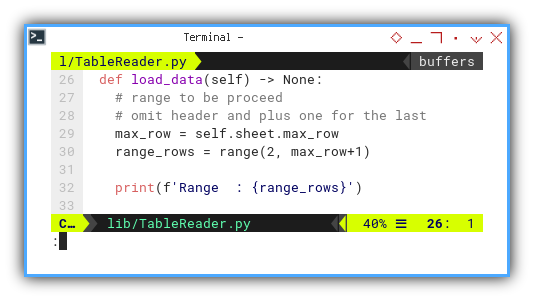
Through the loop, we traverse each row of the worksheet, extracting three values into a new dataframe.
for row in range_rows:
# Convert the new data to a DataFrame
new_row = pd.DataFrame({
"Number" : self.sheet[
f'{self.col_index}{row}'].value,
"Date" : self.sheet[
f'{self.col_date}{row}'].value,
"Category" : self.sheet[
f'{self.col_cat}{row}'].value
}, index=[0])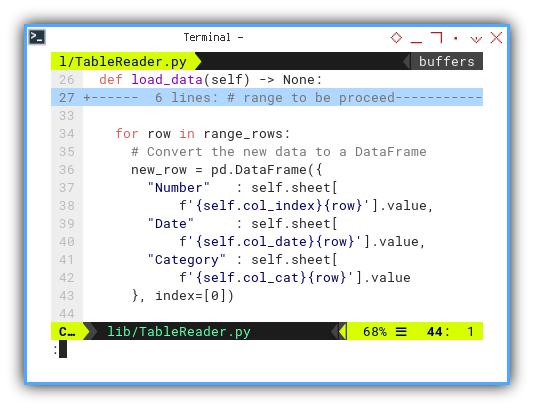
Subsequently, each row is concatenated to append it to the dataframe.
# Append the new row to the existing DataFrame
self.df_table = pd.concat(
[self.df_table, new_row], ignore_index=True)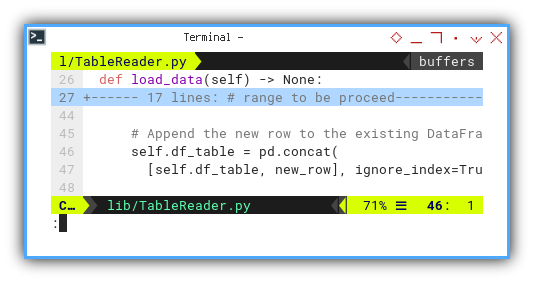
Voila… magic unfolds.
Process
The class follows a straightforward flow.
def process(self) -> None:
self.load_data()Getter
To enhance the organization of internal properties, let’s incorporate getters.
def get_df_table(self) -> DataFrame:
return self.df_tableDisplay
def display(self) -> None:
# Display the header
print("Header:", self.df_table.columns)
# Display the data
print("Data:")
print(self.df_table)
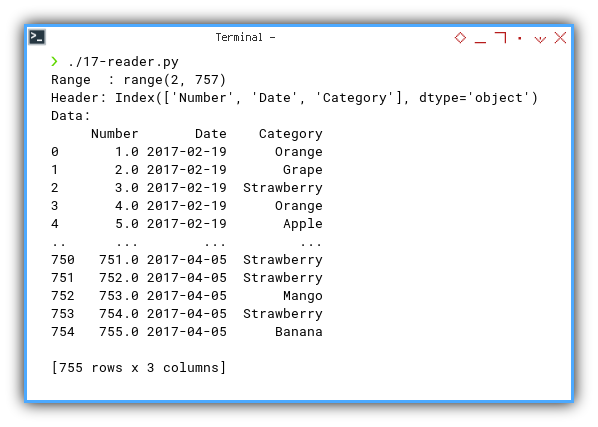
Result Preview
Execute the script in the terminal, and you’ll obtain a text output akin to the example below:
Writer: Main Script
How do I calculate the Pivot with date format?
Considering the distinct date format, the task at hand involves calculating the Pivot and inscribing the result into a worksheet.
Build Pivot
Modifying our preceding class suffices for constructing the Pivot, with only one method requiring adjustment.
from lib.PivotSample import PivotSample
class PivotSampleTS(PivotSample):
def build_pivot(self) -> None:
try:
...
except Exception as e:
print("An error occurred " \
+ f"while processing data: {e}")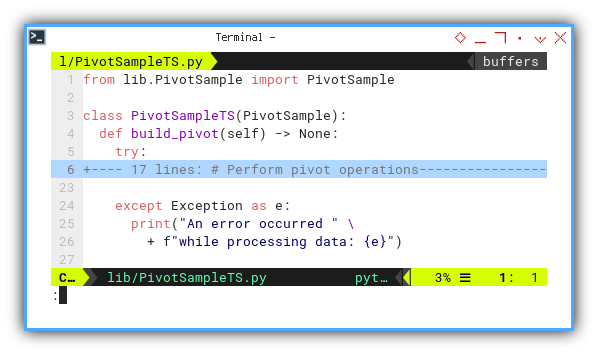
Within the try..except block,
the entire pivot process unfolds:
# Perform pivot operations
df_pivot = self.df_table.pivot_table(
index='Date', columns='Category',
aggfunc='count', fill_value=0)
# Sort the index by both month and day
df_pivot.index = df_pivot. \
index.to_series().apply(lambda x: x.date())
df_pivot = df_pivot.sort_index()
# Ensure all specified columns are present
for cat in self.categories:
if ('Number', cat) not in df_pivot.columns:
df_pivot[('Number', cat)] = 0
# Sort the columns (fruits) in alphabetical order
self.df_pivot = df_pivot.sort_index(axis=1)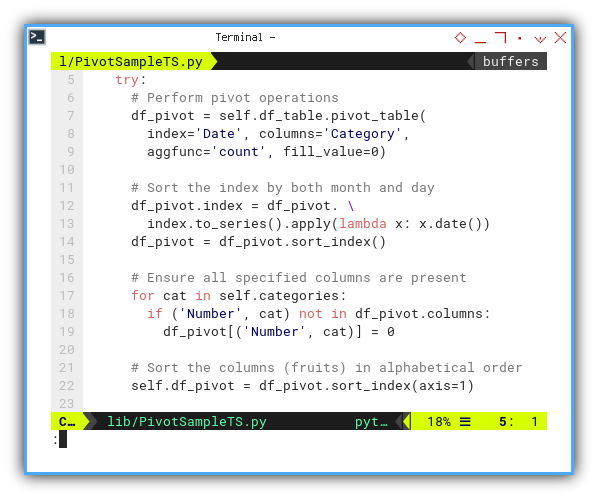
However, the sole alteration is just these line below:
# Ensure all specified columns are present
for cat in self.categories:
if ('Number', cat) not in df_pivot.columns:
df_pivot[('Number', cat)] = 0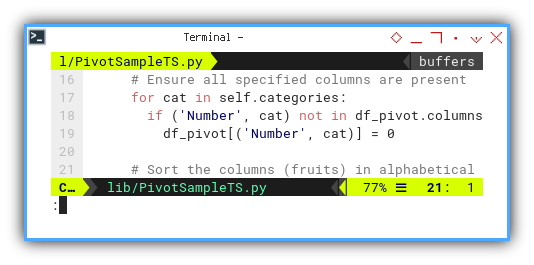
Given that we’re transmitting data from one worksheet to another, we can directly copy the value and sort the date index.
Reader Writer: Main Script
Bringing everything together.
To distinguish the results,
let’s utilize another file named Examples.xlsx,
comprising only the Table worksheet without the Pivot worksheet.
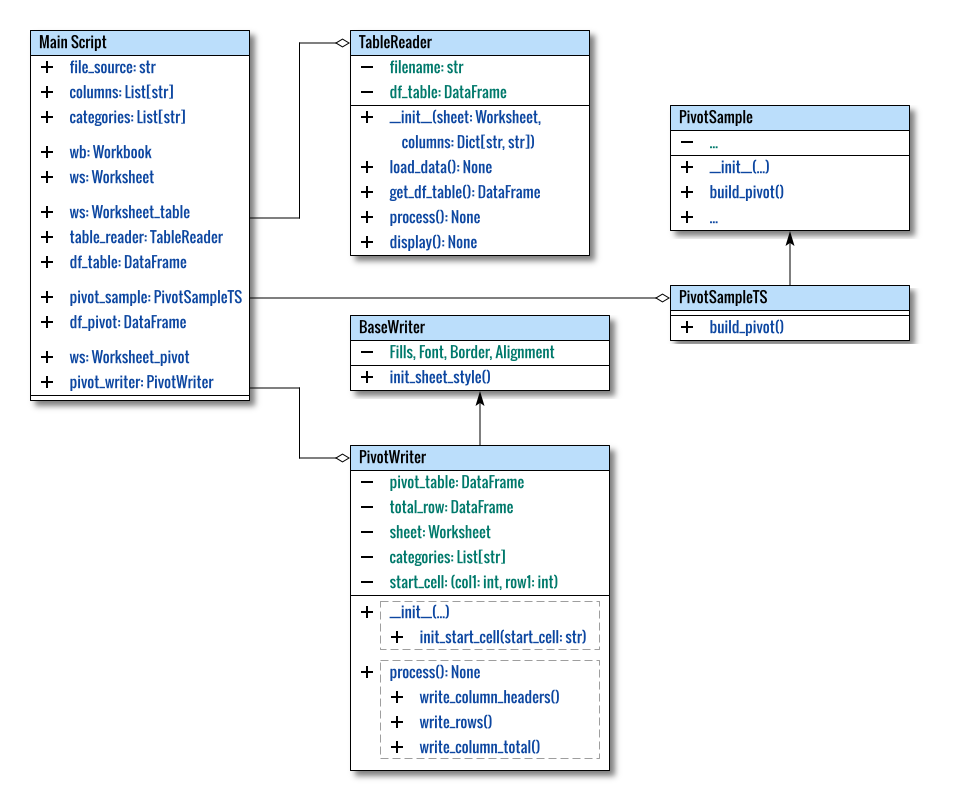
Class Diagram
The adjusted diagram is visualized as follows:
Local Libraries
We need to import three local libraries.
# openPyXL
from openpyxl import Workbook, load_workbook
# Local Library
from lib.TableReader import TableReader
from lib.PivotSampleTS import PivotSampleTS
from lib.PivotWriter import PivotWriter
Directory Structure
This is also reflected as below:
.
├── 18-reader-writer.py
└── lib
├── PivotSampleTS.py
├── TableReader.py
├── BaseWriter.py
└── PivotWriter.pyMain Method
The initial segment involves custom variables, predefined columns for the source sheet, and also categories.
def main() -> None:
file_source = 'Example2.xlsx'
file_target = file_source
columns = {
'index' : 'A',
'date' : 'B',
'cat' : 'C'
}
categories = [
"Apple", "Banana", "Dragon Fruit",
"Durian", "Grape", "Mango",
"Orange", "Strawberry"]
Following that, we handle the source data, which is a worksheet this time.
wb = load_workbook(file_source)
ws = wb['Table']
table_reader = TableReader(ws, columns)
table_reader.process()
table_reader.display()
df_table = table_reader.get_df_table()
pivot_sample = PivotSampleTS(df_table, categories)
pivot_sample.process()
pivot_sample.display()
df_pivot = pivot_sample.get_df_pivot()
Subsequently, we write the pivot as usual, creating a worksheet in the same workbook.
# Create a new sheet
ws = wb.create_sheet(title='Pivot')
wb.active = ws
pivot_writer = PivotWriter(
df_pivot, ws, categories, 'B2')
pivot_writer.process()
# Save the file
wb.save(file_target)
Result
The outcome mirrors the previous workbook.
This time, both sheet—source Table and sheet-target Pivot,
are displayed in the same workbook.
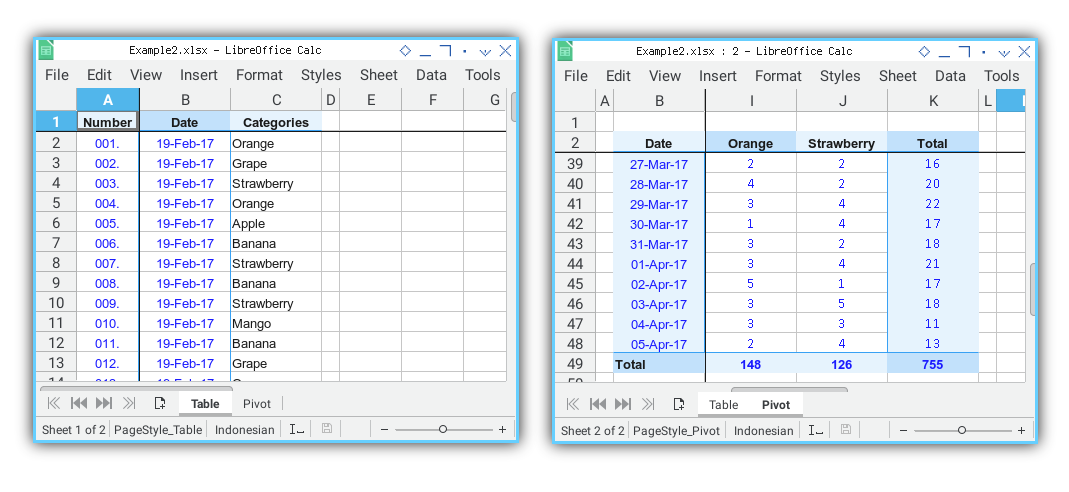
And with that, we conclude.
What Awaits Ahead 🤔?
It’s fantastic that we’ve completed, constructing a pivot using openPyXl entirely. However, why limit ourselves to just one openPyXL solution, when we can also craft a pivot with LibreOffice Calc Macro?
Our next endeavor involves creating a pivot with a Python macro, providing you with a ready-to-use template for common office scenarios.
Interested? Continue reading [ Pivot - Calc Macro - Table Reader ].