Preface
Goal: Convert LibreOffice python macro to UNO python script. Reading from CSV and writing two worksheets.
In the last article of our LibreOffice UNO series,
we’re going to tackle a practical use case:
reading a CSV file and populating
both the Table sheet and the Pivot Sheet.
just like our macro counterpart.
Let’s make it fast. The process involves two scripts:
- 21-reader.py
- 22-reader-writer.py
As mentioned earlier, the primary focus will be on adjusting the loading part. This article would be short. So, let’s dive in.
Reading The CSV
And also writing the table to worksheet.
In this part of our LibreOffice UNO series,
we aim to read data from a previously
generated CSV file, sample-data.csv,
and write the resulting dataframe
to the Table worksheet.
Unlike the macro, UNO allows us to create an instance of an empty sheet out of nowhere.
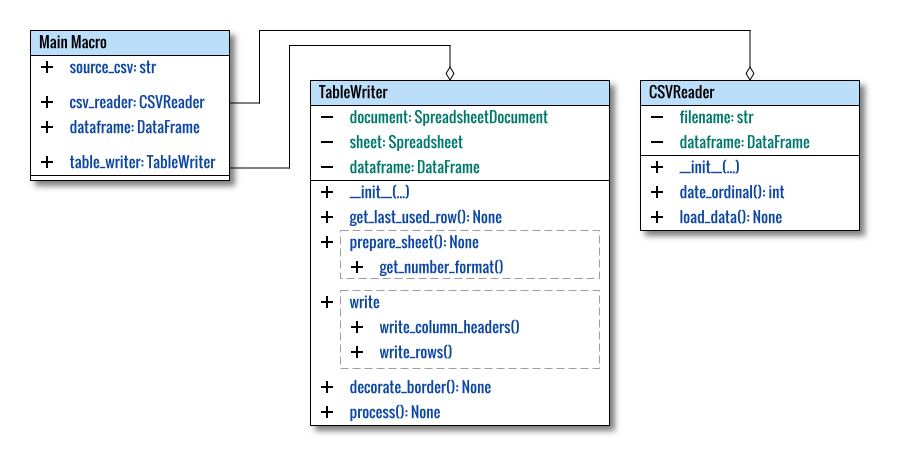
Class Diagram
Let’s begin with a visual representation of this simple yet essential operation:
Directory Structure
.
├── 21-reader.py
└── lib
├── helper.py
├── CSVReader.py
└── TableWriter.pyThe required libraries for this script are detailed below:
Script Skeleton
In this script, we leverage the CSVReader
and the TableWriter classes:
# Local Library
from lib.helper import (
get_desktop, create_calc_instance, get_file_path)
from lib.CSVReader import CSVReader
from lib.TableWriter import TableWriter
def main() -> int:
...
return 0
if __name__ == "__main__":
raise SystemExit(main())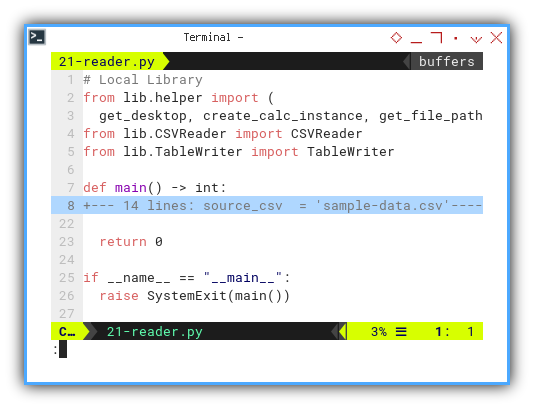
Main Script
We use the dataframe obtained from the CSV
as input for the Table sheet:
def main() -> int:
source_csv = 'sample-data.csv'
csv_reader = CSVReader(source_csv)
csv_reader.process()
dataframe = csv_reader.dataframe
# Getting the source sheet
desktop = get_desktop()
document = create_calc_instance(desktop)
if document:
table_writer = TableWriter(
document, 'Table', dataframe)
table_writer.process()
return 0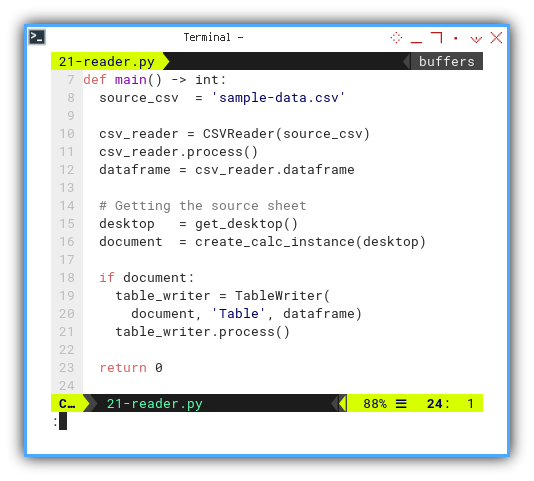
Note that we employ two distinct classes here:
- The
CSVReader(), - The
TableWriter().
The CSVReader Class
This dataframe require a date conversion.
The CSVReader class mirrors its Macro counterpart,
with the additional step of converting the date from the CSV
to an integer type with an offset.
This conversion ensures compatibility with spreadsheet date formats:
import pandas as pd
from datetime import datetime, timedelta
class CSVReader:
def __init__(self, filename: str) -> None:
...
def date_ordinal(self, value, format_source):
...
def load_data(self):
...
def process(self) -> None:
self.load_data()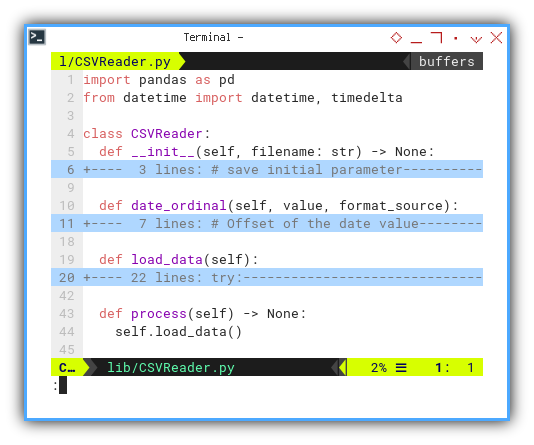
While converting with an ordinal value is optional, it’s a safer approach than omit ordinal conversion, maintaining compatibility with Excel Epoch.
Class: TableWriter: Initialization
The only divergence lies in the initialization section:
class TableWriter:
def __init__(self,
document : 'com.sun.star.frame.XModel',
sheetName: str,
dataframe: DataFrame) -> None:
# save initial parameter
self.document = document
self.dataframe = dataframe
self.sheetName = sheetName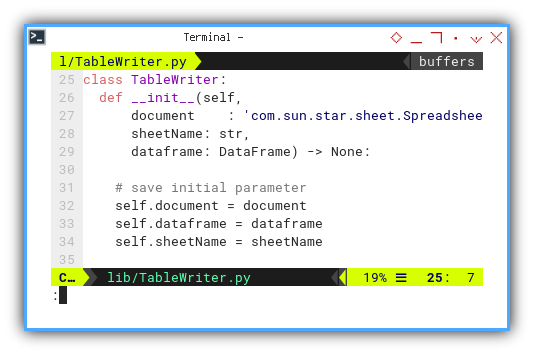
Class: TableWriter: Preparation
And the subsequent initialization:
def prepare_sheet(self):
...
# activate sheet
spreadsheetView = self.document.getCurrentController()
spreadsheetView.setActiveSheet(self.sheet)
The remainder of the process remains consistent.
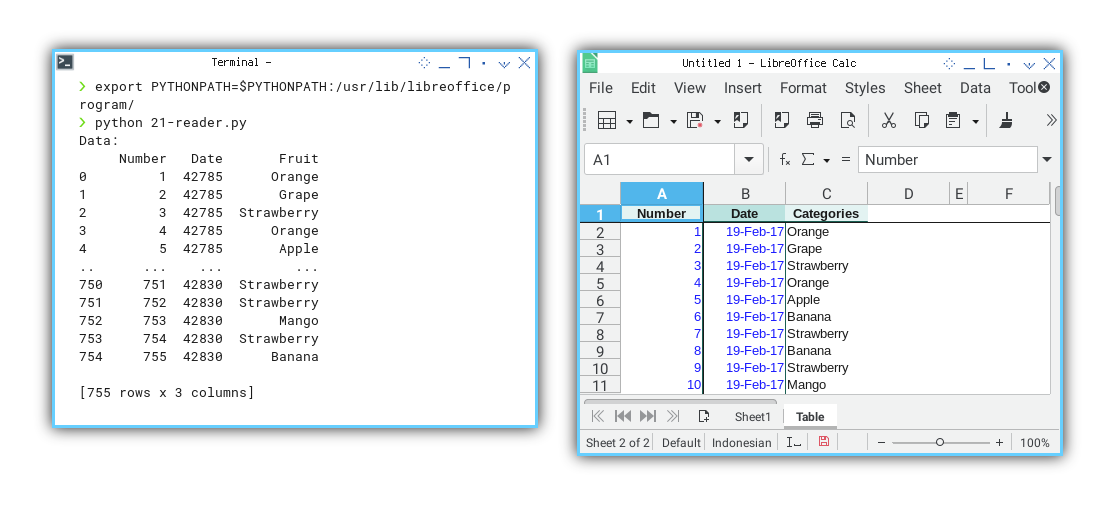
Result Preview
The outcome perfectly aligns, with the results obtained from the macro example:
Writing Pivot Worksheets
Gather All Together
In this segment, we’ll consolidate our efforts
by copying and pasting the previously crafted PivotWriter class
to write the Pivot worksheet.
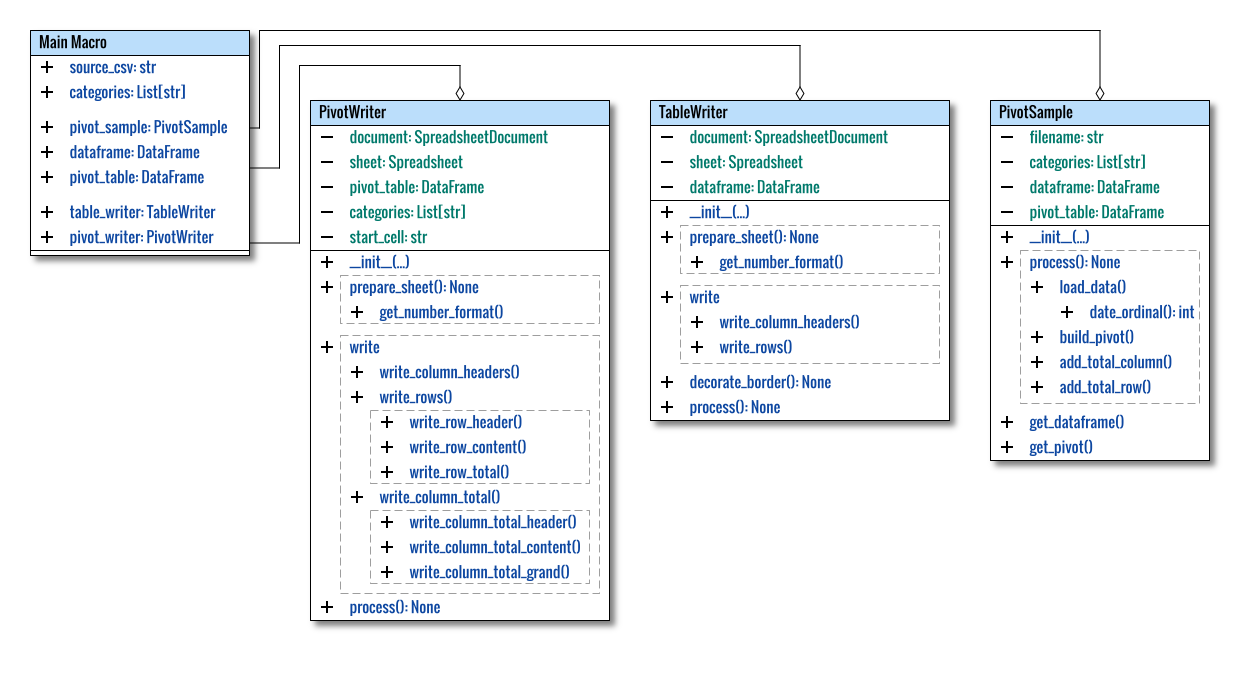
Class Diagram
The entire diagram provides a comprehensive visualization:
Directory Structure
Since we also need to build pivot dataframe,
we are going to use previous PivotSample example.
This is an enhancement of CSVReader,
equipped with pivot dataframe builder.
Since we also need to build a pivot dataframe,
we will utilize the previous PivotSample example.
This is an enhancement of CSVReader,
equipped with a pivot dataframe builder.
.
├── 22-reader-writer.py
└── lib
├── helper.py
├── PivotSample.py
├── TableWriter.py
└── PivotWriter.pyThe required libraries for this script are outlined below:
Script Skeleton
Alongside PivotSample and TableWriter,
we are going to use PivotWriter.
With two sheets to be filled, namely
the Table sheet and the Pivot sheet,
the script structure is as follows:
# Local Library
from lib.helper import (
get_desktop, create_calc_instance, get_file_path)
from lib.PivotSample import PivotSample
from lib.TableWriter import TableWriter
from lib.PivotWriter import PivotWriter
def main() -> int:
...
return 0
if __name__ == "__main__":
raise SystemExit(main())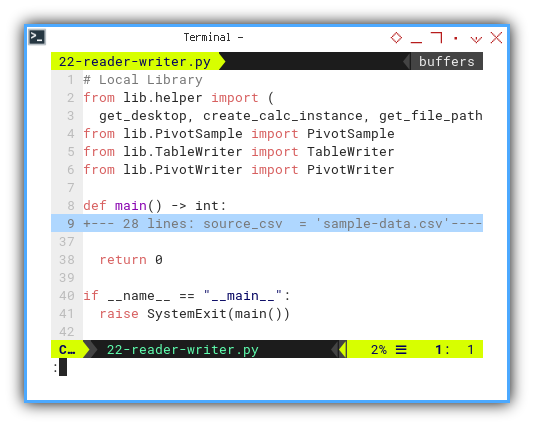
Main Script
From the dataframe result,
we can also transform into the data into pivot dataframe,
then fill the Pivot sheet with prepared values.
We start by filling the table sheet with the dataframe result.
Following that, we transform the data
into a pivot dataframe and proceed
to populate the Pivot sheet with the prepared values.
The initiation of the script involves filling the table sheet:
def main() -> int:
source_csv = 'sample-data.csv'
categories = [
"Apple", "Banana", "Dragon Fruit",
"Durian", "Grape", "Mango",
"Orange", "Strawberry"]
pivot_sample = PivotSample(source_csv, categories)
pivot_sample.process()
dataframe = pivot_sample.get_dataframe()
pivot_table = pivot_sample.get_pivot()
# Print the newly created pivot table on console
print(pivot_table)
print()
return 0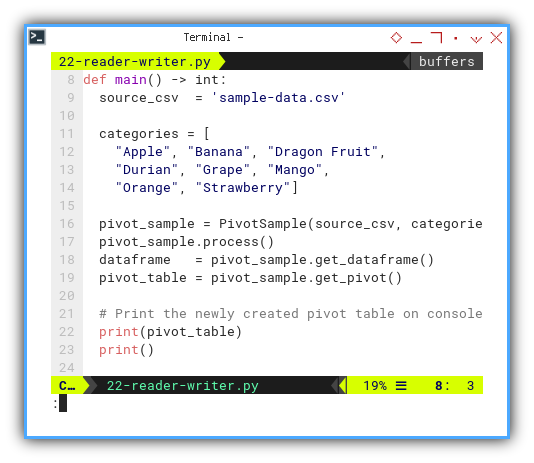
The conclusion of the script centers around filling the pivot sheet:
def main() -> int:
...
# Getting the source sheet
desktop = get_desktop()
document = create_calc_instance(desktop)
if document:
table_writer = TableWriter(document,
'Table', dataframe)
table_writer.process()
writer = PivotWriter(document,
'Pivot', pivot_table, categories, 'B2')
writer.process()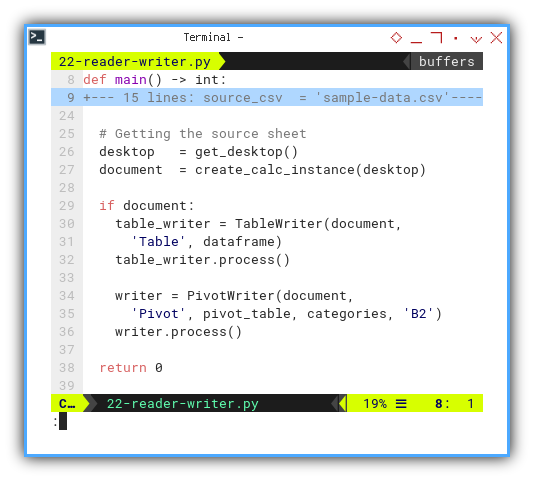
Now, with both sheets, Table and Pivot, our task is complete.
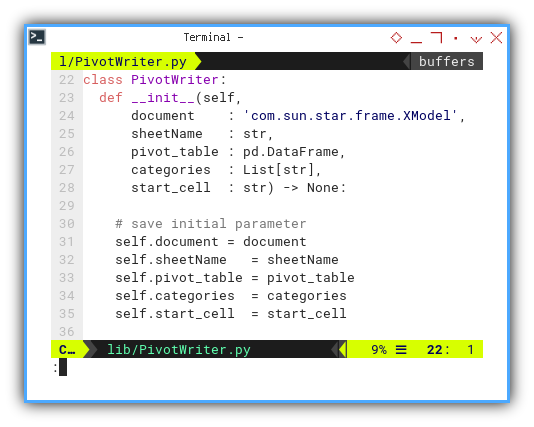
Class: PivotWriter: Initialization
The only discrepancy lies in the initialization part,
along with the preparation to obtain the model object:
class PivotWriter:
def __init__(self,
document : 'com.sun.star.sheet.SpreadsheetDocument',
sheetName : str,
pivot_table : pd.DataFrame,
categories : List[str],
start_cell : str) -> None:
# save initial parameter
self.document = document
self.sheetName = sheetName
self.pivot_table = pivot_table
self.categories = categories
self.start_cell = start_cell
...
There is absolutely nothing novel in this example. After all, it is merely a migration from a Python macro to a Python UNO script.
Activity Diagram
As a summary, the entire process can be depicted in this chronological order:
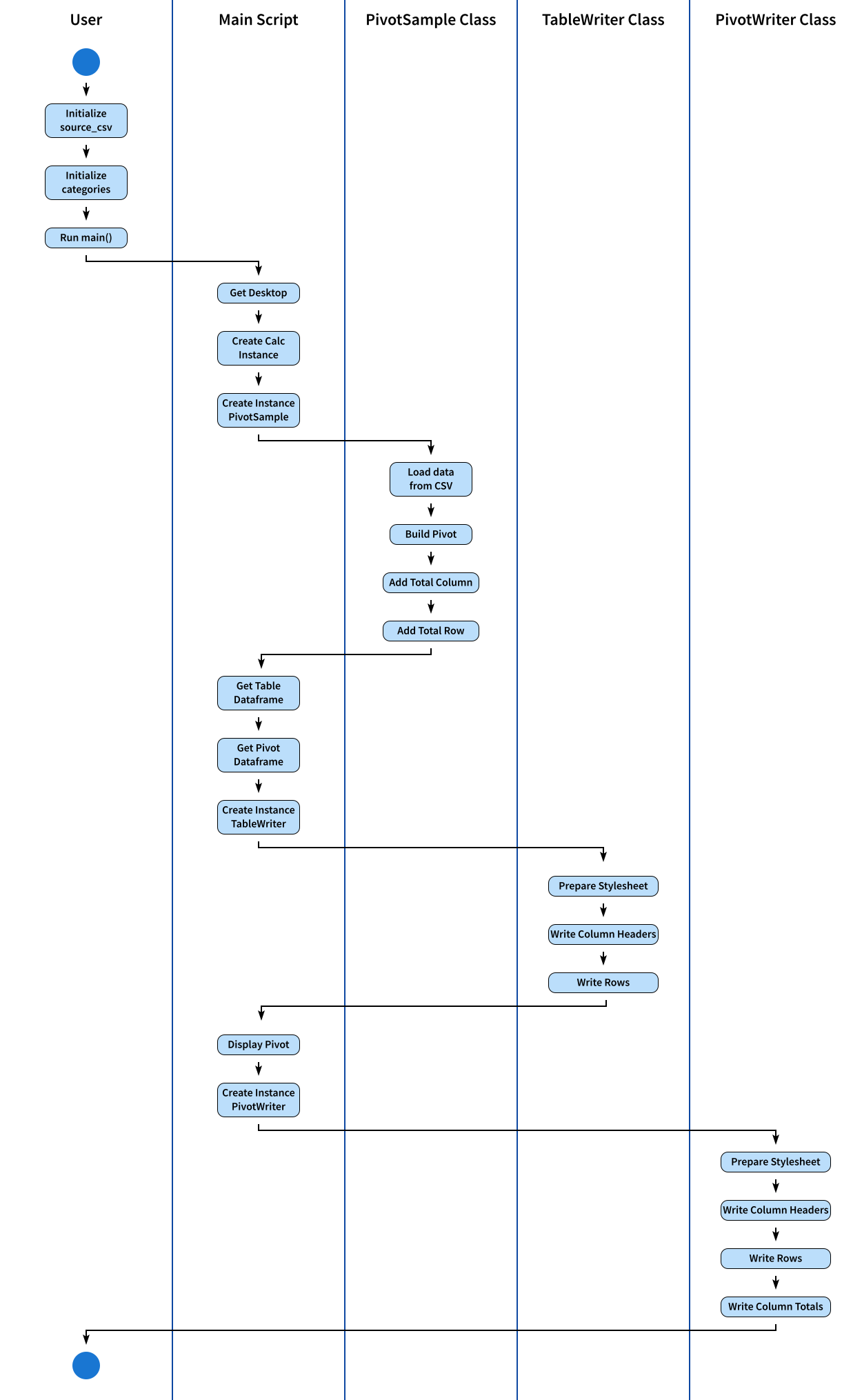
Result Preview
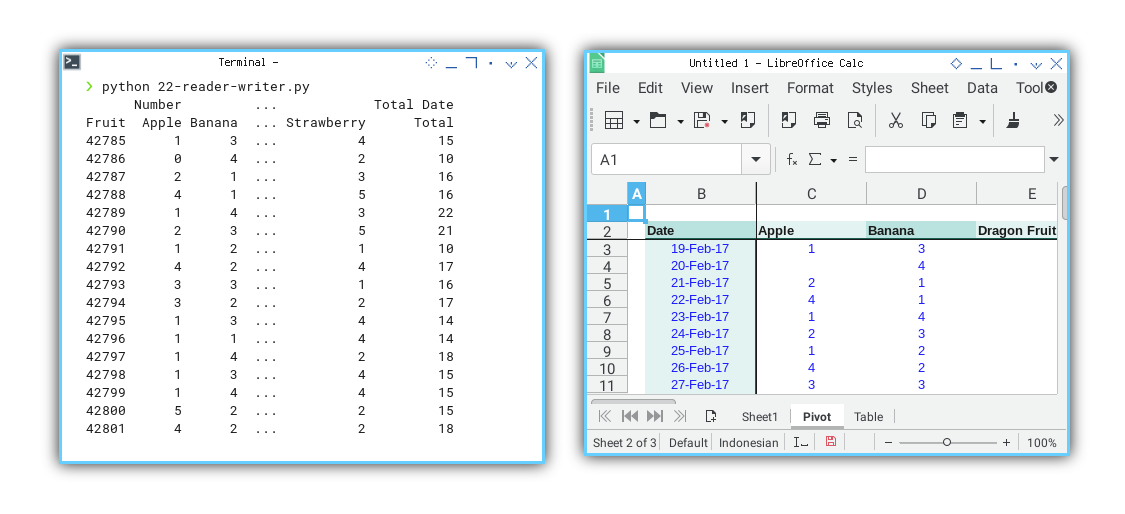
The outcome mirrors precisely hat we achieved with the macro example:
What’s the Next Exciting Step 🤔?
I’m going to take a brief pause and catch my breath before delving into the realm of Python’s easy-to-use OOO Dev library.
Consider continuing your exploration by reading [ Pivot - LO OOO - Open Instance ].