Preface
Goal: Prepare data modelling by making a random data generator.
All that’s required is a single CSV file.
Library
This script requires the following library:
import csv, random
from datetime import datetime, timedelta
from pprint import pprintData Specification
Each row consists of the following two elements:
- Random date within a specified range.
- Random category chosen from predefined categories.
Consider a scenario where we own a fruit shop in a quaint town. We anticipate gathering sales data over a specific timeframe. For instance, we can define the time span as follows:
start_date = datetime(2017, 2, 19)
end_date = start_date + timedelta(days=45)Assuming the shop sells a variety of popular fruits, we can categorize them as follows:
categories = ["Apple", "Banana", "Orange",
"Grape", "Strawberry", "Mango"]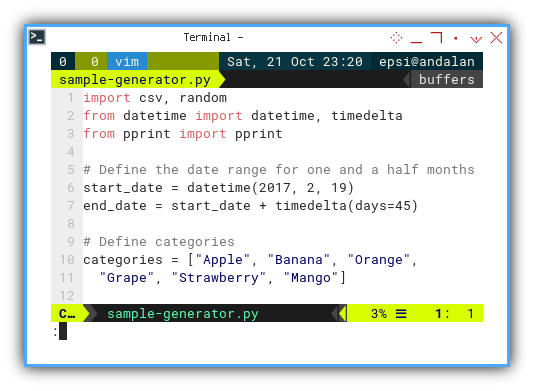
Simulate Excel Feature
In Excel, you have the ability to introduce a category into a pivot table that doesn’t exist in the original table. I aim to simulate this zero count feature in our generated data.
To achieve this, I introduce a rare fruit into the predefined categories. This fruit has no sales records since the fruit shop doesn’t actually sell them.
categories = ["Apple", "Banana", "Orange",
"Grape", "Strawberry", "Durian", "Mango", "Dragon Fruit"]
zero_count_categories = ["Durian", "Dragon Fruit"]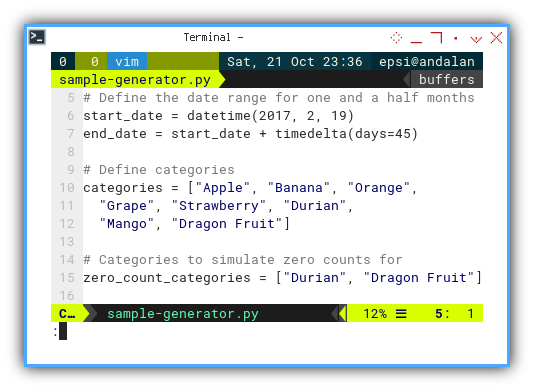
Alternatively, you have the option to modify the category later, outside the generator script.
The Row Generator
Before creating the CSV file, we can generate in-memory data, as a simple Python list of lists.
Simple Category
The loop for generating data with a simple category can be illustrated as follows:
data = []
for i in range(1, 1001):
current_date = start_date \
+ timedelta(days=random.randint(0, 45))
category = random.choice(categories)
data.append([
current_date.strftime("%d/%m/%Y"), category])
pprint(data)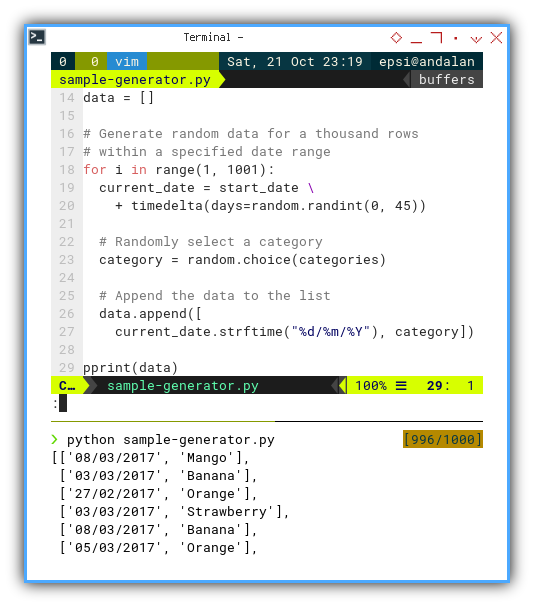
Simulating Zero Category
The loop for simulating zero category can be depicted as follows:
data = []
for i in range(1, 1001):
current_date = start_date \
+ timedelta(days=random.randint(0, 45))
category = random.choice(categories)
if category in zero_count_categories:
# Simulate zero count by skipping
continue
data.append([
current_date.strftime("%d/%m/%Y"), category])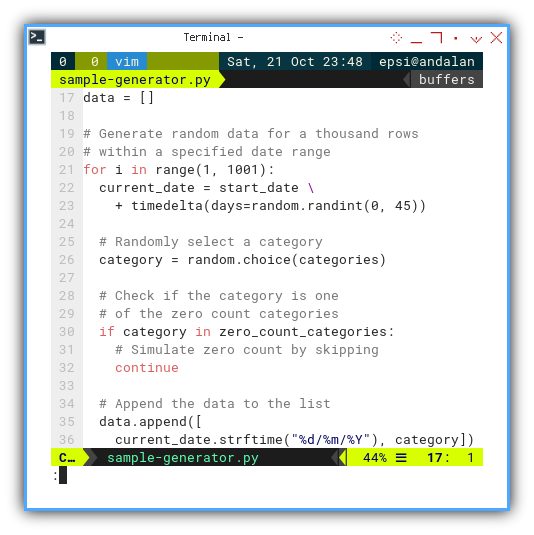
Sorting and Index
To ensure proper organization,
we need to sort the data based on the date.
This can be achieved using a lambda function
with the help of strptime:
data.sort(
key=lambda x: datetime.strptime(x[0],
"%d/%m/%Y"))And adding index can be done, by inserting the numbering column while enumerating each row:
for i, row in enumerate(data):
row.insert(0, i + 1)The resulting data would look like this:
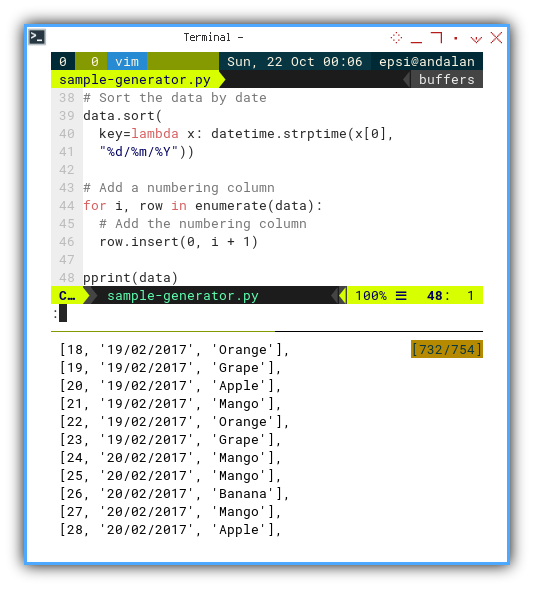
You can observe how the date changes in an ordered manner after a few lines.
Saving CSV
Saving a CSV file is a straightforward process, as demonstrated in the example below:
# Add a header
header = ["Number", "Date", "Fruit"]
# Write the data to a CSV file with header
with open('sample_data.csv',
mode='w', newline='') as file:
writer = csv.writer(file)
writer.writerow(header)
writer.writerows(data)
print("Sample data has been generated "
+ "and saved to 'sample-data.csv'.")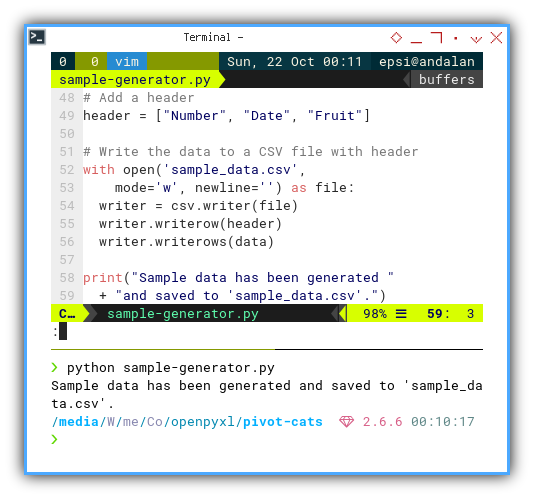
CSV File
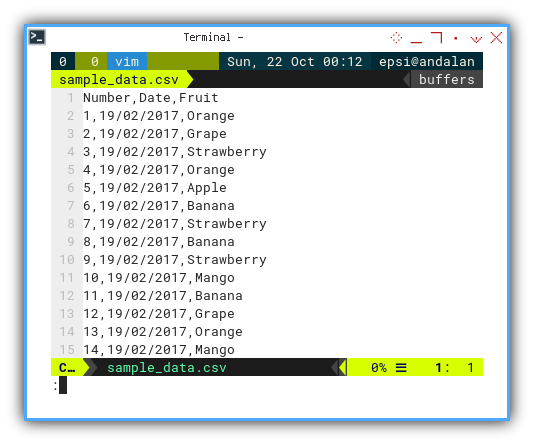
The resulting raw data in the CSV file would look like this:
Number,Date,Fruit
1,19/02/2017,Orange
2,19/02/2017,Grape
3,19/02/2017,Strawberry
4,19/02/2017,Orange
5,19/02/2017,Apple
6,19/02/2017,Banana
7,19/02/2017,Strawberry
8,19/02/2017,Banana
9,19/02/2017,Strawberry
10,19/02/2017,Mango
11,19/02/2017,Banana
12,19/02/2017,Grape
13,19/02/2017,Orange
14,19/02/2017,Mango
15,19/02/2017,Strawberry
16,20/02/2017,Orange
17,20/02/2017,Mango
18,20/02/2017,Banana
19,20/02/2017,Mango
20,20/02/2017,Strawberry
Importing CSV
You can import the CSV file using Microsoft Excel or LibreOffice Calc. Ensure that you import the date in the appropriate date format,
not as a string.
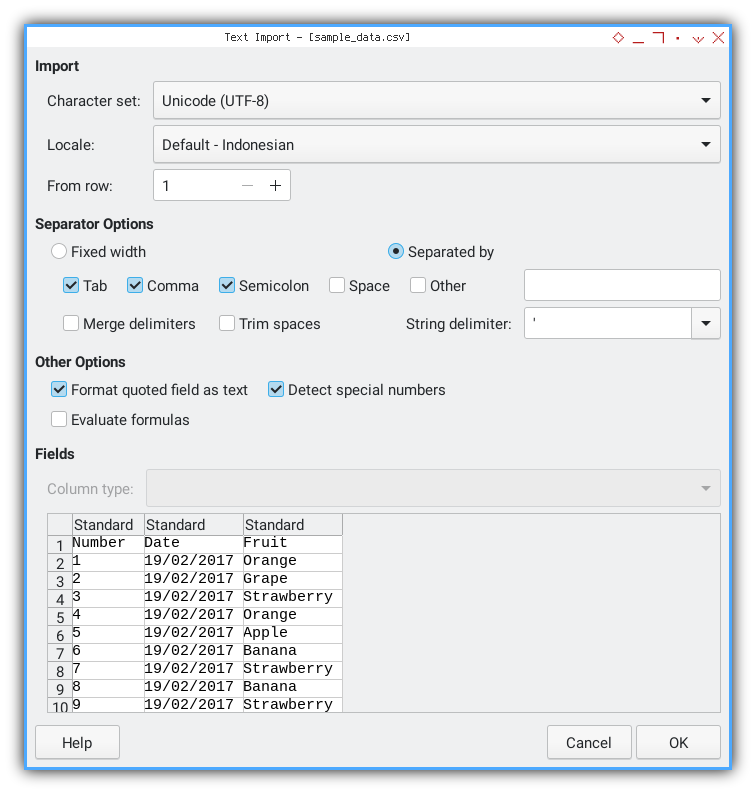
The resulting worksheet will appear like this. With value highlighting, you can observe that the date is not imported as a string.
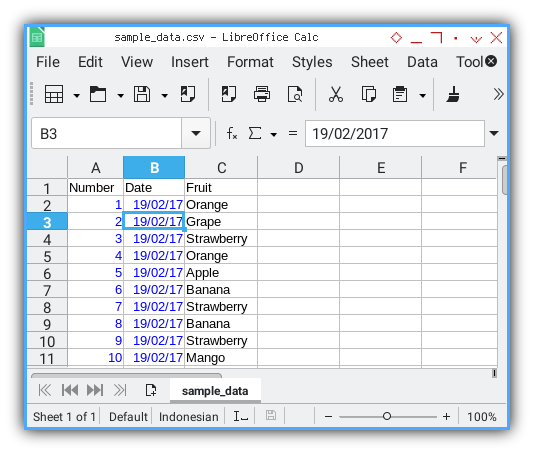
Finally, rename the worksheet as Table.
Then save it as Example.xlsx.
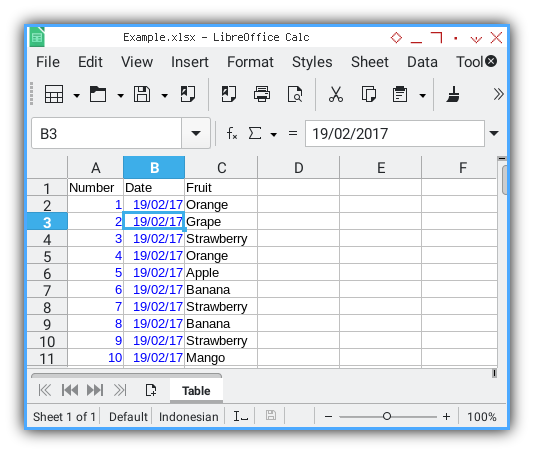
In this article series, we will use either the CSV or XLSX file as a source for data modeling, depending on the case.
Example CSV and Worksheet
For convenience I’m providing both the raw data in .csv,
and also the worksheet in .xlsx format here
This way you can enjoy persistent example, and compare it with other method, ithout worrying changes, each time new example data is generated.
What Awaits Us Next 🤔?
While a dataframe comes with its own CSV reader, the list comprehension requires us to manually craft our own CSV reader.
Consider continuing to read [ Pivot - Model - CSV Reader ].