Preface
Goal: A practical case to collect unique record fields using Perl.
Perl5 is not a dead language. It is still widely used.
But if you need to evolve, you should consider Raku (formerly Perl6).
Reference Reading
The last time I read perl documentation thoroughly, was two decades ago.
Source Examples
You can obtain source examples here:
Common Use Case
Task: Get the unique tag string
Please read overview for more detail.
Prepopulated Data
Songs and Poetry
package MySongs;
use strict;
use warnings;
our @songs = (
{ title => 'Cantaloupe Island',
tags => ['60s', 'jazz'] },
{ title => 'Let It Be',
tags => ['60s', 'rock'] },
{ title => 'Knockin\' on Heaven\'s Door',
tags => ['70s', 'rock'] },
{ title => 'Emotion',
tags => ['70s', 'pop'] },
{ title => 'The River'},
);Perl Solution
The Answer
I use list comprehension like syntax using map and grep.
One of them is this oneliner as below:
use MySongs;
my %seen;
my @songs_tags = grep {
!$seen{$_}++
} map {
@{ $_->{'tags'} }
} grep {
exists($_->{'tags'})
} @MySongs::songs;
say join(":", @songs_tags);Enough with introduction, at this point we should go straight to coding.
Environment
No need any special setup. Just run and voila..!
1: Data Structure Using Dictionary
We can use list or array.
But array in data structure is easier to handle.
So we are going to use array,
throught out this article.
Simple List
Consider begin with simple list.
my @tags = ('rock',
'jazz', 'rock', 'pop', 'pop');
print join(':', @tags) . "\n";It is easy to dump array in perl using join.
With the result similar as below list:
❯ perl 01-tags-a.pl
rock:jazz:rock:pop:pop
Simple Array
How about array?
#!/usr/bin/perl
use strict;
use warnings;
sub say {print @_, "\n"}
my $tags_ref = ['rock',
'jazz', 'rock', 'pop', 'pop'];
say join(':', @$tags_ref);Alternatively, you can use say, instead of perl.
❯ perl 01-tags-b.pl
rock:jazz:rock:pop:pop
Quote Word
Alternative syntax.
#!/usr/bin/perl
use 5.010;
use strict;
use warnings;
my @tags = qw<rock jazz rock pop pop>;
say join ':', @tags;With the result similar as below joined string:
❯ perl 01-tags-c.pl
rock:jazz:rock:pop:pop
Default Header Declaration
For most of the perl script I use the same header as below:
#!/usr/bin/perl
use 5.010;
use strict;
use warnings;Shebang
With shebang such as #!/usr/bin/perl,
you do not need to type perl in CLI.
Instead of
❯ perl 02-song.plYou can just type
❯ ./02-song.plAnd you can run the script directly in your text editor.
Such as using geany, you just can hit the F5 key to run the script.
Hash
We can use hash to store our record.
my %song = (
title => 'Cantaloupe Island',
tags => ['60s', 'jazz']
);And examine how to access the array inside the hash.
my $tags = $song{tags};
say $song{title};
say join(":", @$tags);
say $song{tags}[1];You should be careful with these symbol:
$for scalar,@for array, and%for hash.- Conversion such as
@$for array representation.
Now, examine the result:
❯ ./02-song.pl
Cantaloupe Island
60s:jazz
jazz
The Songs Structure
We can continue our journey to records using array of hash.
No need any complex structure.
#!/usr/bin/perl
use 5.010;
use strict;
use warnings;
my @songs = (
{ title => 'Cantaloupe Island',
tags => ['60s', 'jazz'] },
{ title => 'Let It Be',
tags => ['60s', 'rock'] },
{ title => 'Knockin\' on Heaven\'s Door',
tags => ['70s', 'rock'] },
{ title => 'Emotion',
tags => ['70s', 'pop'] },
{ title => 'The River'}
);Then process in a loop to produce desired output.
for (@songs) {
my %song_hash = %$_;
if (exists $song_hash{'tags'}) {
my $tags = $song_hash{'tags'};
say $song_hash{'title'} . " is "
. join(":", @$tags);
}
}With the result similar as below record:
❯ ./03-songs.pl
Cantaloupe Island is 60s:jazz
Let It Be is 60s:rock
Knockin' on Heaven's Door is 70s:rock
Emotion is 70s:popFiltering Approach
I’m using exists to test if the hash certain key.
exists $song_hash{'tags'}There will be other alternatives as well.
2: Separating Module
Since we need to reuse the songs record multiple times, it is a good idea to separate the record structure from logic.
Songs Module
The code can be shown as below:
Notice the extension is .pm instead of .pl.
package MySongs;
use strict;
use warnings;
our @songs = (
{ title => 'Cantaloupe Island',
tags => ['60s', 'jazz'] },
{ title => 'Let It Be',
tags => ['60s', 'rock'] },
{ title => 'Knockin\' on Heaven\'s Door',
tags => ['70s', 'rock'] },
{ title => 'Emotion',
tags => ['70s', 'pop'] },
{ title => 'The River'},
);
Module in Relative Path
In order to use module in relative path, we need to add a few more header declaration.
use File::Basename;
use lib dirname(__FILE__);
use MySongs;
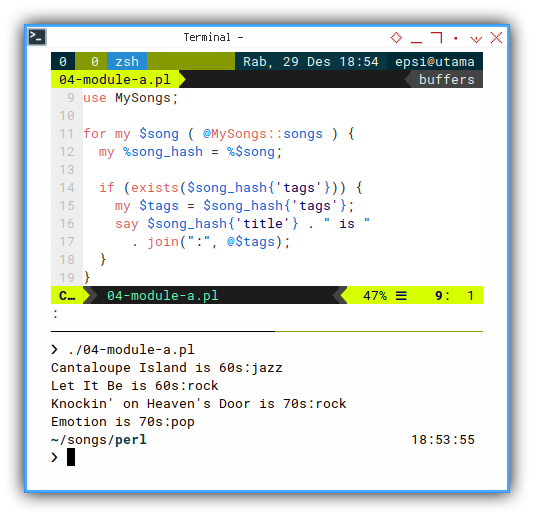
Using Songs Module
Now we can have a shorter code as shown below.
for my $song ( @MySongs::songs ) {
my %song_hash = %$song;
if (exists($song_hash{'tags'})) {
my $tags = $song_hash{'tags'};
say $song_hash{'title'} . " is "
. join(":", @$tags);
}
}With the result exactly the same as previous code.
Using Default Variable
We can even rewrite code above to be a very short code, with advantage of perl syntax.
for (@MySongs::songs) {
if (exists $_->{'tags'}) {
say @$_{'title'} . " is "
. join(":", @{ $_->{'tags'} });
}
}The result is, exactly the same as previous code.
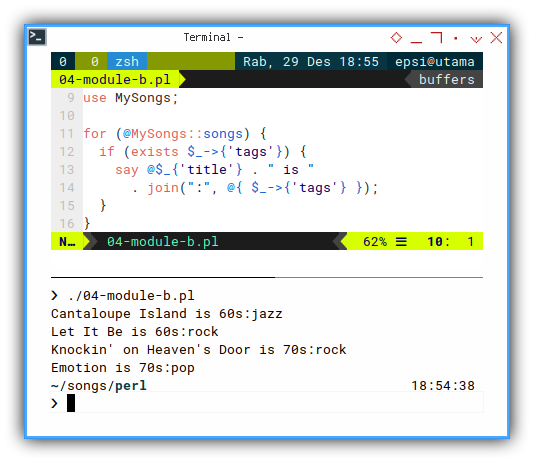
❯ ./04-module-b.pl
Cantaloupe Island is 60s:jazz
Let It Be is 60s:rock
Knockin' on Heaven's Door is 70s:rock
Emotion is 70s:pop3: Finishing The Task
Extract, Flatten, Unique
We can solve, this task,
by using imperative approach,
such as for loop.
And later we can build,
a list comprehension like appproach,
utilizing map and grep.
Extracting Hash
Filtering hash, and push to array
Consider start with this long code:
my @tagss = ();
for my $song ( @MySongs::songs ) {
my %song_hash = %$song;
if (exists($song_hash{'tags'})) {
push @tagss, $song_hash{'tags'};
}
}
for my $tags ( @tagss ) {
say join(":", @$tags);
}With the result of array of array, as shown below.
❯ ./05-extract-a.pl
60s:jazz
60s:rock
70s:rock
70s:pop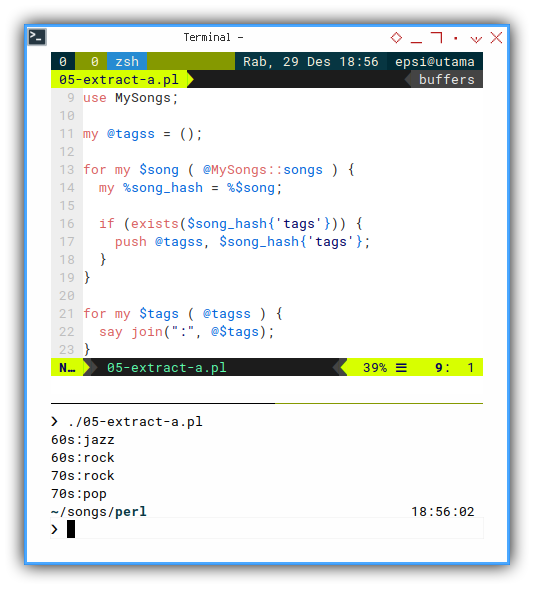
We can also have compacted version of above code.
my @tagss = ();
for (@MySongs::songs) {
if (exists $_->{'tags'} ) {
push @tagss, $_->{'tags'};
}
}
for (@tagss) {
say join(":", @$_);
}With exactly the same result.
Filtering Using Keys.
We can also utilize keys as below:
my @tagss = ();
for (@MySongs::songs) {
if (grep /tags/, keys %$_) {
push @tagss, $_->{'tags'};
}
}With exactly the same result.
Flatten Function
To flatten the code above, we can directly push array with this code below:
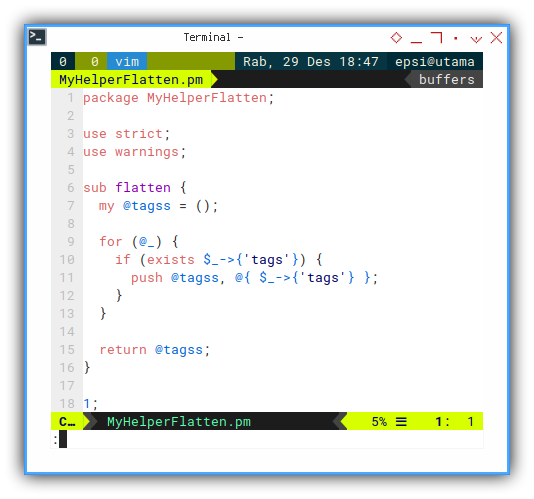
push @tagss, @{ $_->{'tags'} };Since we are going to reuse the flatten approach above in other script. It is better to bundle the script in its own perl module.
package MyHelperFlatten;
use strict;
use warnings;
sub flatten {
my @tagss = ();
for (@_) {
if (exists $_->{'tags'}) {
push @tagss, @{ $_->{'tags'} };
}
}
return @tagss;
}
1;The return values is an array.
Using Flatten Module
There is nothing to say in this code below.
Just apply flatten function to our song records.
use MySongs;
use MyHelperFlatten;
say join(":",
MyHelperFlatten::flatten(
@MySongs::songs));With the result of a flattened array shown below.
❯ ./06-flatten.pl
60s:jazz:60s:rock:70s:rock:70s:popUnique
To solve unique array,
we can use code taken from stackoverflow below:
sub unique {
my %seen;
grep !$seen{$_}++, @_;
}And applying to our previous code:
say join(":",
unique(
MyHelperFlatten::flatten(
@MySongs::songs
)));With the result similar as below array:
❯ ./07-unique.pl
60s:jazz:rock:70s:pop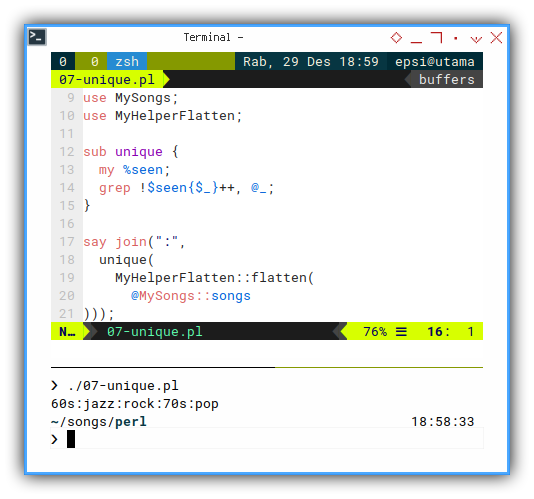
What is Next 🤔?
We have alternative way to extract the record structure. With pattern similar to list comprehension.
Consider continue reading [ Perl - Playing with Records - Part Two ].