Preface
Goal: Utilizing GNU Awk for string processing.
Using awk for text processing is even easier than BASH.
This awk is also utilizing regular expression,
but it is still easier than sed counterparts.
Reference Reading
You need to read the official document first, before you read this article.
Especially about FS, ORS and such stuff.
Source Examples
You can obtain source examples here:
Common Use Case
Task: Get the unique tag string
Please read overview for more detail.
Data Structure Support
We are going to use external text file,
consist of CSV like field.
Prepopulated Data
Songs and Poetry
The data is simply a text file.
Cantaloupe Island; 60s,jazz
Let It Be;60s,rock
Knockin' on Heaven's Door; 70s, rock
Emotion; 70s, pop
The River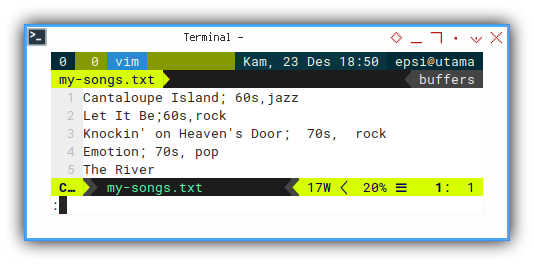
AWK Solution
The Answer
It is long, with dignity.
#!/bin/awk -f
BEGIN {
FS="[;,]"
i = 0
}
{
gsub(/;[ ]+/,";")
gsub(/,[ ]+/,",")
$1=""
OFS=":"
$1=$1;
split($0, tags_temp, ":")
for (j in tags_temp)
if (j > 1)
tags[++i] = tags_temp[j]
}
END {
i=0
for (t in tags) {
if ( !exist[tags[t]]++ ) {
unique[++i] = tags[t]
}
}
ORS=":"
for (u in unique) {
if (u == i) ORS="\n"
print unique[u]
}
}Enough with introduction, at this point we should go straight to coding.
Environment
No need any special setup. Just run and voila..!
1: Field in AWK
We are going to check how far awk,
can handle data structure.
Simple Array
Consider begin with simple line contain this field below.
rock, jazz,rock, pop, popThen we can process the text file with awk directly with code below:
#!/bin/awk -f
BEGIN {
FS=",";
OFS=":";
}
{
gsub(/,[ ]+/,",");
$1=$1;
print "|", $3, "|\t", $0;
}
END { }With output result as below:
❯ ./01-tags.awk my-tags.txt
|:rock:| :rock:jazz:rock:pop:pop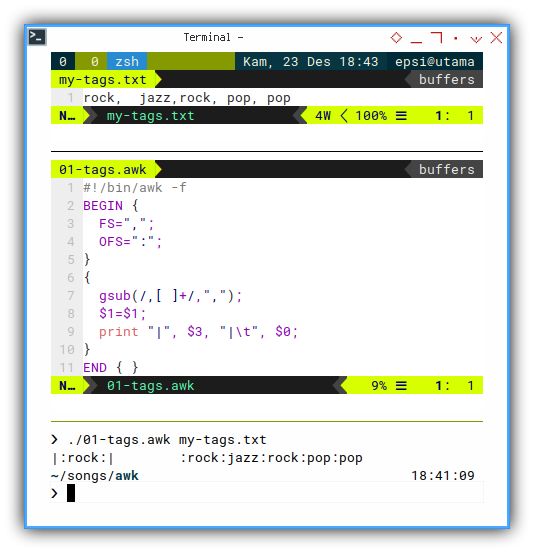
Record
Now consider this form,
to process my-songs.json above.
#!/bin/awk -f
BEGIN {
FS="[;,]"
}
{
gsub(/;[ ]+/,";")
gsub(/,[ ]+/,",")
title=$1
$1=""
OFS=":"
$1=$1
OFS=" "
print title, "is", $0
}
END { }With output result as below:
❯ ./02-song.awk my-songs.txt
Cantaloupe Island is :60s:jazz
Let It Be is :60s:rock
Knockin' on Heaven's Door is :70s:rock
Emotion is :70s:pop
The River is 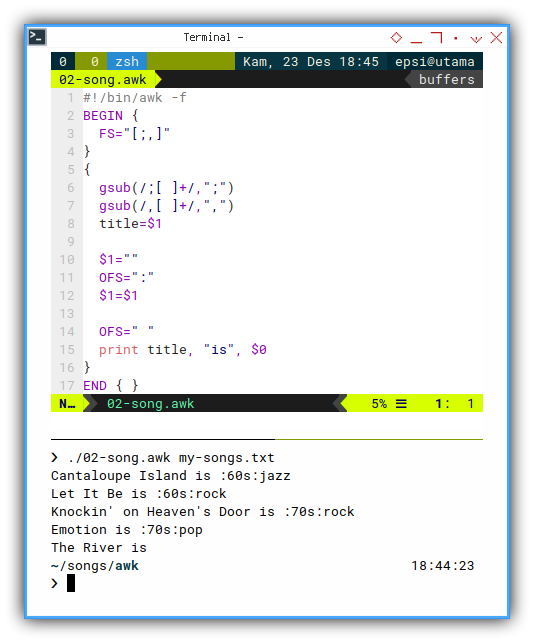
Field Separator
First, it has two field separator.
- The Semicolon
;, and - The Comma
,.
BEGIN {
FS="[;,]"
}How does it works?
For each line do this:
-
Save the first occurence in
titlevariable. -
Remove the first occurrences
$1="". -
Rebuild with
$1=$1.
2: Finishing The Task
Extract, Flatten, Unique
Extract and Flatten
Based on the result above,
we can go further, extracting the tags data.
We can just print the tags separated with delimiter.
#!/bin/awk -f
BEGIN {
FS="[;,]"
ORS=""
}
{
gsub(/;[ ]+/,";")
gsub(/,[ ]+/,",")
$1=""
OFS=":"
$1=$1;
print $0
}
END {
print "\n"
}With the result of tags, as shown below.
❯ ./03-songs.awk my-songs.txt
:60s:jazz:60s:rock:70s:rock:70s:pop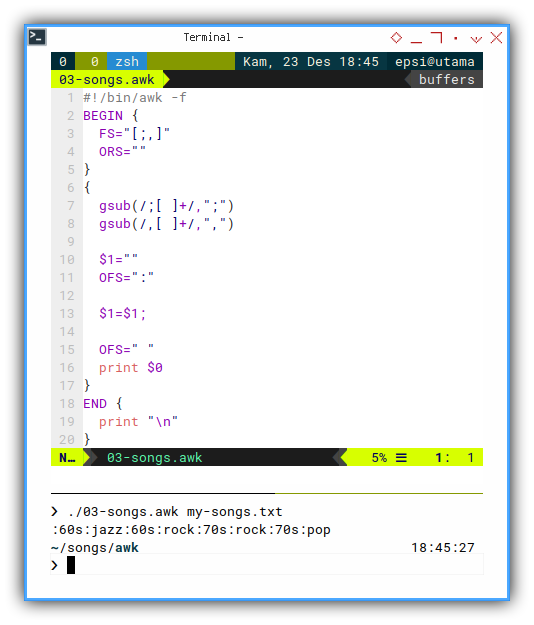
Notice how we join each line with empty ORS.
ORS=""Flatten Using Variable
Instead of relying to displayed character,
we can use variable instead to flatten.
awk support array thagt can only be accessed by index.
Now we can normalize, the separated values. Flatten all values into just single array.
First, we initialize variable.
#!/bin/awk -f
BEGIN {
FS="[;,]"
i = 0
}Then append the tags array in the loop.
{
gsub(/;[ ]+/,";")
gsub(/,[ ]+/,",")
$1=""
OFS=":"
$1=$1;
split($0, tags_temp, ":")
for (j in tags_temp)
if (j > 1)
tags[++i] = tags_temp[j]
}Finally we print with delimiter. Except for the last line, I use newline as delimiter.
END {
ORS=":"
for (k in tags) {
if (k == i) ORS="\n"
print tags[k]
}
}With the result of a flattened array shown below.
❯ ./04-flatten.awk my-songs.txt
60s:jazz:60s:rock:70s:rock:70s:popUnique
We can solve unique value with pure awk.
I found the script in google search,
and I already adapt the script for my own.
It is basically the same with previous awk.
#!/bin/awk -f
BEGIN {
FS="[;,]"
i = 0
}And this part is also almost similar.
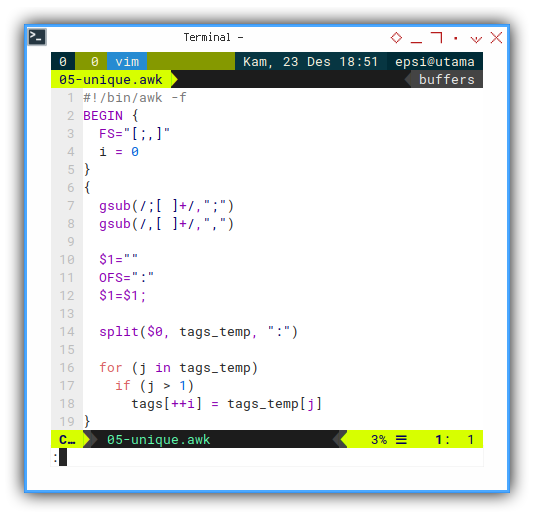
{
gsub(/;[ ]+/,";")
gsub(/,[ ]+/,",")
$1=""
OFS=":"
$1=$1;
split($0, tags_temp, ":")
for (j in tags_temp)
if (j > 1)
tags[++i] = tags_temp[j]
}
With array index, we can spot which tag is exist.
Then we can display as usual.
END {
i=0
for (t in tags) {
if ( !exist[tags[t]]++ ) {
unique[++i] = tags[t]
}
}
ORS=":"
for (u in unique) {
if (u == i) ORS="\n"
print unique[u]
}
}With the result similar as below array:
❯ ./05-unique.awk my-songs.txt
60s:jazz:rock:70s:pop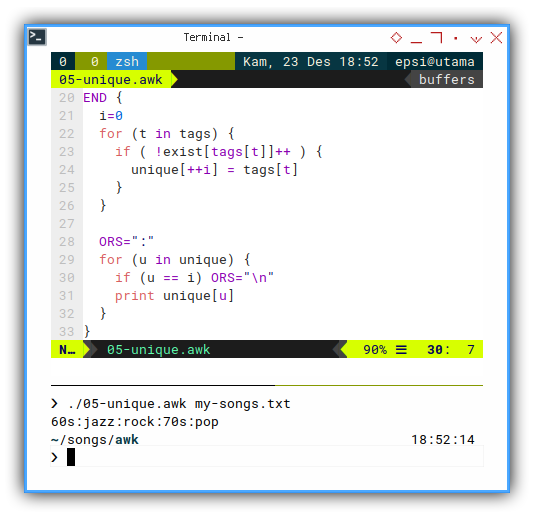
It is so easy to learn, if you willing to read the offical documentation.
That is all.
What is Next 🤔?
Consider continue reading [ Sed - Playing with Records ].