Preface
Goal: A practical case to collect unique record fields using Python.
What I think about python is large community base.
Reference Reading
The last time I read python documentation thoroughly, was two decades ago. There have been some changes, and interesting things.
Source Examples
You can obtain source examples here:
Common Use Case
Task: Get the unique tag string
Please read overview for more detail.
Prepopulated Data
Songs and Poetry
songs = [
dict( title = 'Cantaloupe Island',
tags = ['60s', 'jazz'] ),
dict( title = 'Let It Be',
tags = ['60s', 'rock'] ),
dict( title = 'Knockin\' on Heaven\'s Door',
tags = ['70s', 'rock'] ),
dict( title = 'Emotion',
tags = ['70s', 'pop'] ),
dict( title = 'The River')
]Python Solution
The Answer
I use list comprehension a lot. One of them is this oneliner as below:
from MySongs import songs
tags = [
tag for song in songs
if 'tags' in song
for tag in song['tags']
]
print(list(set(tags)))Enough with introduction, at this point we should go straight to coding.
Environment
No need any special setup. Just run and voila..!
1: Data Structure Using Dictionary
We are going to use list and dictionary,
throught out this article.
Simple List
Consider begin with simple list.
tags = ["rock", "jazz", "rock", "pop", "pop"]
print(tags)It is easy to dump variable in python using print.
With the result similar as below list:
❯ python 01-tags.py
['rock', 'jazz', 'rock', 'pop', 'pop']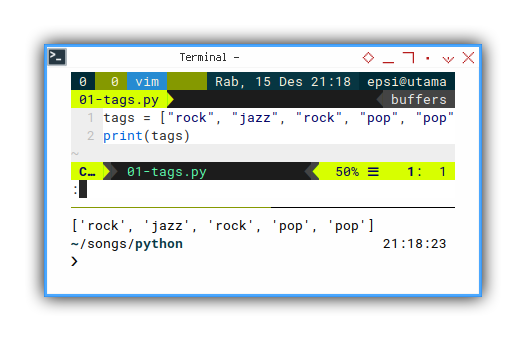
Dictionary
There are different way to write dictionary.
The choice is your preferences.
I mostly uses bracket for my project,
which is the simpler one.
But for this record project,
I prefer the dict form.
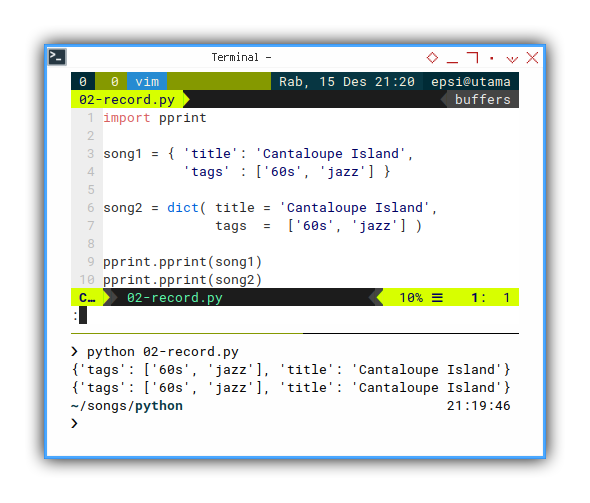
import pprint
song1 = { 'title': 'Cantaloupe Island',
'tags' : ['60s', 'jazz'] }
song2 = dict( title = 'Cantaloupe Island',
tags = ['60s', 'jazz'] )
pprint.pprint(song1)
pprint.pprint(song2)The python standard library has this pprint.
Now with python we can output structure data, in tidier form.
This means we can examine better,
for any bug, or whatsoever.
❯ python 02-record.py
{'tags': ['60s', 'jazz'], 'title': 'Cantaloupe Island'}
{'tags': ['60s', 'jazz'], 'title': 'Cantaloupe Island'}As we can examine in output result above, both dictionaries represent the very same structure.
The Songs Structure
We can continue our journey to records just using dictionary.
No need any complex structure.
from pprint import pprint
songs = [
dict( title = 'Cantaloupe Island',
tags = ['60s', 'jazz'] ),
dict( title = 'Let It Be',
tags = ['60s', 'rock'] ),
dict( title = 'Knockin\' on Heaven\'s Door',
tags = ['70s', 'rock'] ),
dict( title = 'Emotion',
tags = ['70s', 'pop'] ),
dict( title = 'The River')
]
pprint(songs)With the result similar as below record:
❯ python 03-songs.py
[{'tags': ['60s', 'jazz'], 'title': 'Cantaloupe Island'},
{'tags': ['60s', 'rock'], 'title': 'Let It Be'},
{'tags': ['70s', 'rock'], 'title': "Knockin' on Heaven's Door"},
{'tags': ['70s', 'pop'], 'title': 'Emotion'},
{'title': 'The River'}]2: Separating Module
Since we need to reuse the songs record multiple times, it is a good idea to separate the record structure from logic.
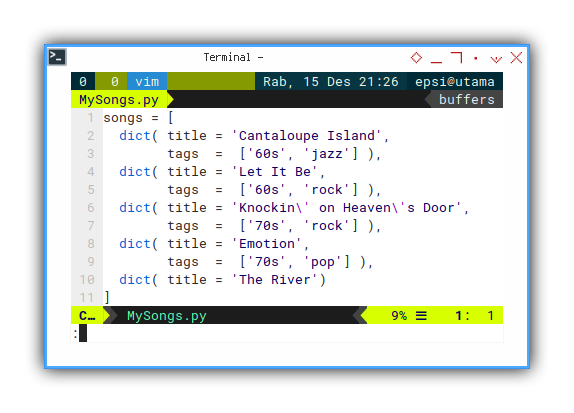
Songs Module
The code can be shown as below:
songs = [
dict( title = 'Cantaloupe Island',
tags = ['60s', 'jazz'] ),
dict( title = 'Let It Be',
tags = ['60s', 'rock'] ),
dict( title = 'Knockin\' on Heaven\'s Door',
tags = ['70s', 'rock'] ),
dict( title = 'Emotion',
tags = ['70s', 'pop'] ),
dict( title = 'The River')
]
Using Songs Module
Now we can have a very short code.
from pprint import pprint
from MySongs import songs
pprint(songs)With the result exactly the same as above dictionary.
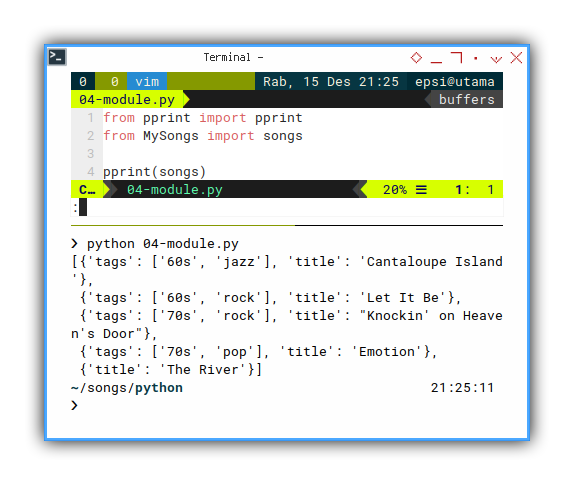
❯ python 04-module.py
[{'tags': ['60s', 'jazz'], 'title': 'Cantaloupe Island'},
{'tags': ['60s', 'rock'], 'title': 'Let It Be'},
{'tags': ['70s', 'rock'], 'title': "Knockin' on Heaven's Door"},
{'tags': ['70s', 'pop'], 'title': 'Emotion'},
{'title': 'The River'}]3: Finishing The Task
Extract, Flatten, Unique
Extracting Dictionary
List comprehension, and nothing else
The only addition is filter
from pprint import pprint
from MySongs import songs
tagss = [
song['tags'] for song in songs
if 'tags' in song
]
pprint(tagss)With the result of list of list, as shown below.
❯ python 05-extract.py
[['60s', 'jazz'], ['60s', 'rock'], ['70s', 'rock'], ['70s', 'pop']]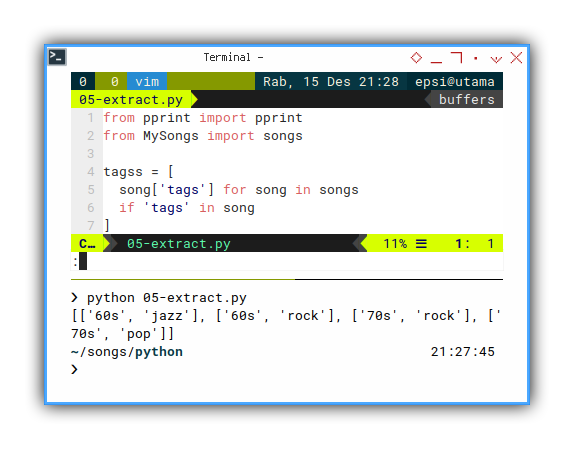
You can go further with map and filter,
but I’m going to skip these map and filter part.
Flatten
Advance List Comprehension
Again, what we need is only list comprehension. But two level list comprehension is a little bit tricky.
Consider begin with separating the list comprehension.
from pprint import pprint
from MySongs import songs
tagss = [
song['tags'] for song in songs
if 'tags' in song
]
tags = [
tag for tags in tagss
for tag in tags
]
pprint(tags)With the result of a flattened list shown below.
❯ python 06-flatten-a.py
['60s', 'jazz', '60s', 'rock', '70s', 'rock', '70s', 'pop']We can rewrite above statement, as two level loop:
a = []
for tags in tagss:
for tag in tags:
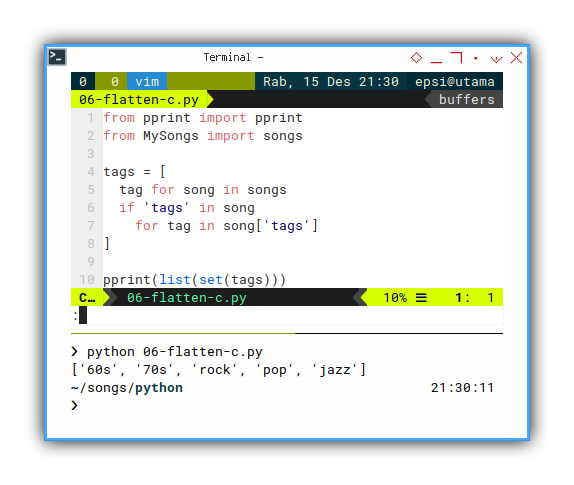
a.append(tag)And finally we can unified as oneline list comprehension.
tags = [
tag for song in songs
if 'tags' in song
for tag in song['tags']
]With the result exactly the same as previous advance list.
Unique
To solve unique list,
we can convert a list to a set,
and convert back the unique set to a list.
from MySongs import songs
tags = [
tag for song in songs
if 'tags' in song
for tag in song['tags']
]
print(list(set(tags)))With the result similar as below array:
❯ python 07-unique.py
['jazz', 'rock', '70s', '60s', 'pop']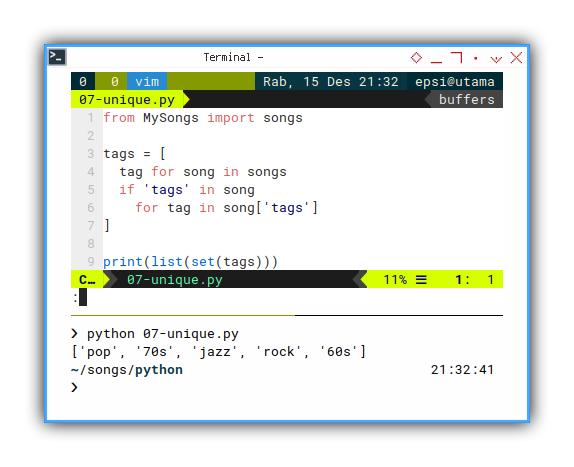
Very short, right?
What is Next 🤔?
We have alternative way to build the record structure.
Consider continue reading [ Python - Playing with Records - Part Two ].