Preface
Goal: Convert LibreOffice python macro to UNO python script. Reading and writing the same sheet.
This time is simpler since we can divide each class into different library files. Given that the majority of the code remains consistent with the macro example, there’s no need to reiterate every explanation.
Let’s expedite the process. We have the following files:
- 11-dataframe.py
- 12-pivot.py
- 13-writer.py
- 14-deco.py
- 15-total.py
The only aspect we need to modify is the loading part.
Preparing The Dataframe
This script essentially loops through a range of rows in a worksheet, concatenating the values into a dataframe.
With the ability to read and write into a worksheet, your basic scripting skills are sufficient for straightforward data processing. You can experiment with any bulk of worksheet data for practice.
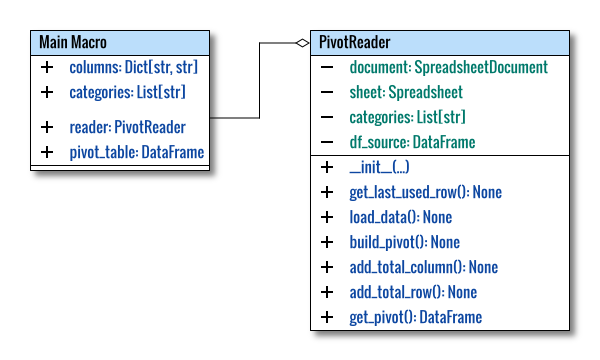
Class Diagram
Learning becomes more accessible with an initial visualization. This is a starting-point diagram, not strictly adhering to standard UML diagram conventions.
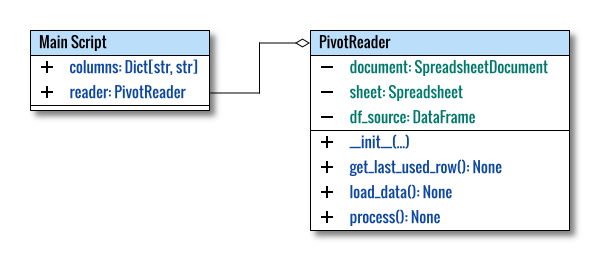
The class diagram above was created using multiple pages in Inkscape. The source can be obtained here for your adaptation.
{kind=link}
Directory Structure
.
├── 11-dataframe.py
└── lib
├── helper.py
└── PivotReader11You can also observe the required library in the script below:
Script Skeleton
We are going to use this PivotReader11.
import pandas as pd
# Local Library
from lib.helper import (
get_desktop, open_document, get_file_path)
from lib.PivotReader11 import PivotReader
def main() -> int:
...
return 0
if __name__ == "__main__":
raise SystemExit(main())
I’ve also added a return value, so that the script can exit gracefully.
Main Script
The initial part of the script involves variable initialization.
def main() -> int:
columns = {
'index' : 'A',
'date' : 'B',
'cat' : 'C'
}
pd.set_option('display.max_rows', 10)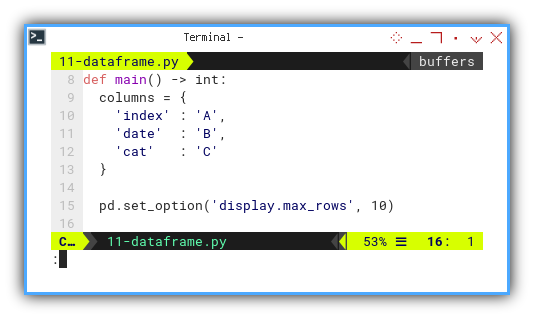
The concluding part of the script, includes the sheet instance and class instance.
# Getting the source sheet
file_path = get_file_path('Example.ods')
desktop = get_desktop()
document = open_document(desktop, file_path)
if document:
reader = PivotReader(
document, 'Table', columns)
reader.process()
return 0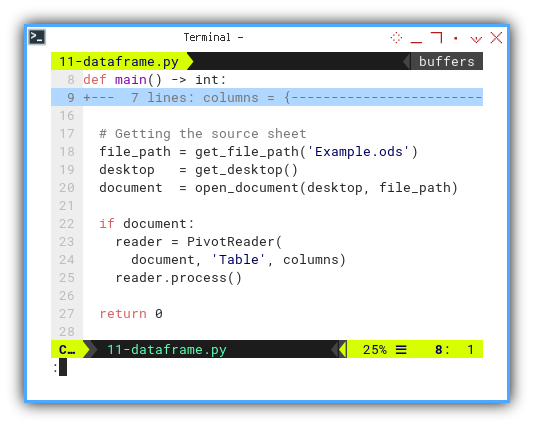
Class: PivotReader: Initialization
You can simply copy and paste our previous Python macro, and adapt it to the Python UNO script. The only difference lies in the initialization part.
class PivotReader:
def __init__(self,
document : 'com.sun.star.sheet.SpreadsheetDocument',
sheetName : str,
columns : Dict[str, str]) -> None:
# save initial parameter
self.document = document
self.sheet = self.document. \
Sheets[sheetName]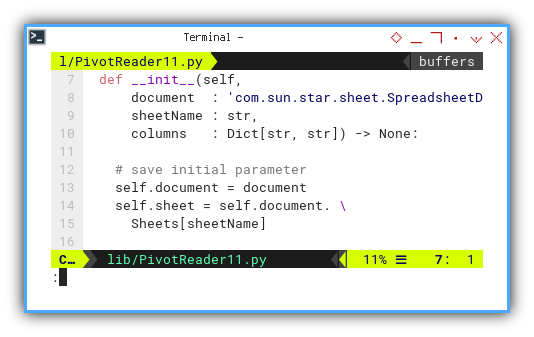
After obtaining this document, the remainder of the process is the same as in the macro example.
def __init__(self,
...
# Unpack the dictionary keys and values
# into class attributes
for key, value in columns.items():
setattr(self, f"col_{key}", value)
# initialize dataframe
self.df_source = pd.DataFrame({
"Number": [], "Date": [], "Category": [] })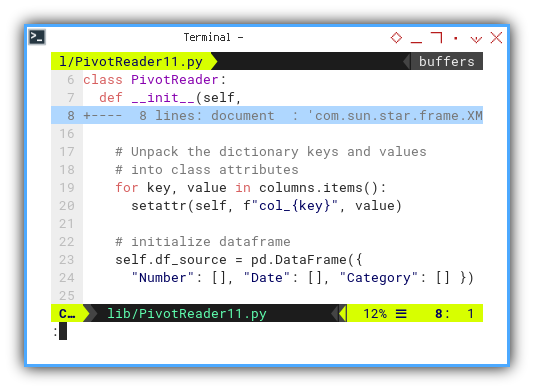
The subsequent methods also remain unchanged.
Result Preview
Now you can witness the reading result of the table.
❯ python 11-dataframe.py
Range : range(2, 757)
Number Date Category
0 1.0 42785.0 Orange
1 2.0 42785.0 Grape
2 3.0 42785.0 Strawberry
3 4.0 42785.0 Orange
4 5.0 42785.0 Apple
.. ... ... ...
750 751.0 42830.0 Strawberry
751 752.0 42830.0 Strawberry
752 753.0 42830.0 Mango
753 754.0 42830.0 Strawberry
754 755.0 42830.0 Banana
[755 rows x 3 columns]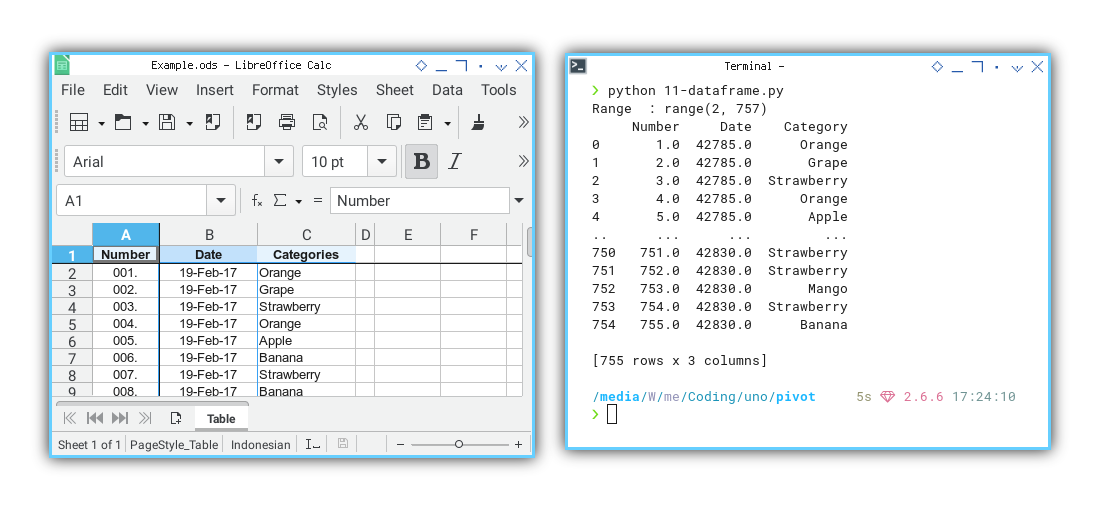
The source is the sheet on the left, and the result is displayed in the terminal on the right.
Building Pivot
From the resulting dataframe, we can transform the data into a pivot dataframe.
Class Diagram
Below is an improved diagram:
Directory Structure
.
├── 12-pivot.py
└── lib
├── helper.py
└── PivotReaderYou can also observe the required library in the script below:
Script Skeleton
import pandas as pd
# Local Library
from lib.helper import (
get_desktop, open_document, get_file_path)
from lib.PivotReader import PivotReader
def main() -> int:
...
return 0
if __name__ == "__main__":
raise SystemExit(main())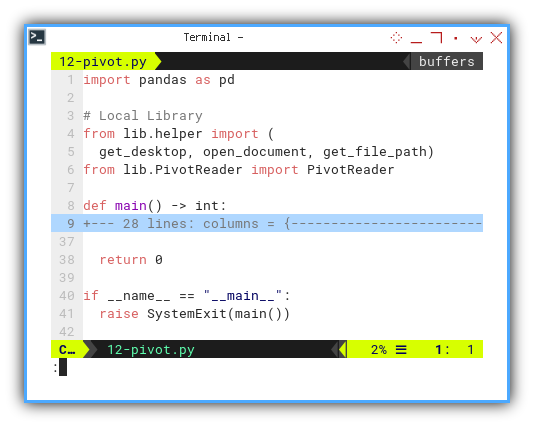
Main
def main() -> int:
columns = {
'index' : 'A',
'date' : 'B',
'cat' : 'C'
}
categories = [
"Apple", "Banana", "Dragon Fruit",
"Durian", "Grape", "Mango",
"Orange", "Strawberry"]
pd.set_option('display.max_rows', 10)
pd.set_option('display.max_columns', 5)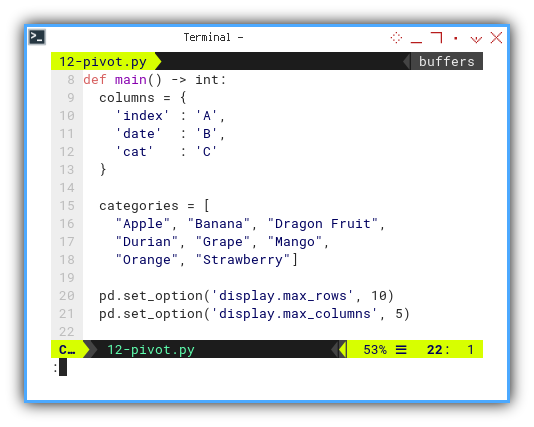
# Getting the source sheet
file_path = get_file_path('Example.ods')
desktop = get_desktop()
document = open_document(desktop, file_path)
if document:
reader = PivotReader(document,
'Table', columns, categories)
pivot_table = reader.get_pivot()
# Print the newly created pivot table
# on terminal console for monitoring
print(pivot_table)
print()
return 0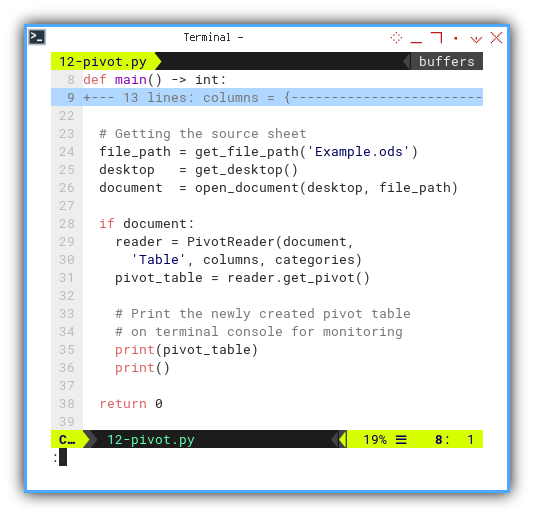
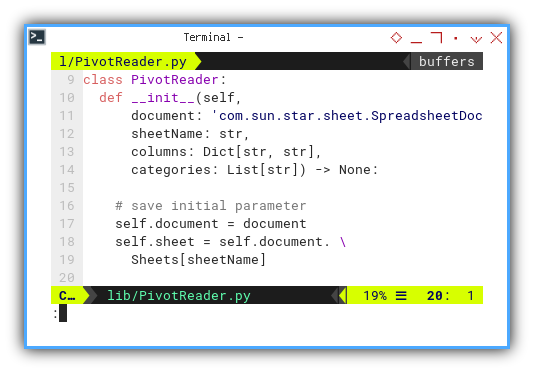
Class: PivotReader: Initialization
The initialization is precisely the same as in the previous script. However, the rest of the class has been enhanced, copied from the previous Python macro.
class PivotReader:
def __init__(self,
document : 'com.sun.star.sheet.SpreadsheetDocument',
sheetName : str,
columns : Dict[str, str]) -> None:
# save initial parameter
self.document = document
self.sheet = self.document. \
Sheets[sheetName]
...
The subsequent steps remain the same.
Result Preview
Now we can observe the pivot result.
❯ python 12-pivot.py
Range : range(2, 757)
Number ... Total Date
Category Apple Banana ... Strawberry Total
42785.0 1 3 ... 4 15
42786.0 0 4 ... 2 10
42787.0 2 1 ... 3 16
42788.0 4 1 ... 5 16
42789.0 1 4 ... 3 22
... ... ... ... ... ...
42827.0 1 1 ... 1 17
42828.0 4 0 ... 5 18
42829.0 0 2 ... 3 11
42830.0 3 1 ... 4 13
Total 114 125 ... 126 755
[47 rows x 9 columns]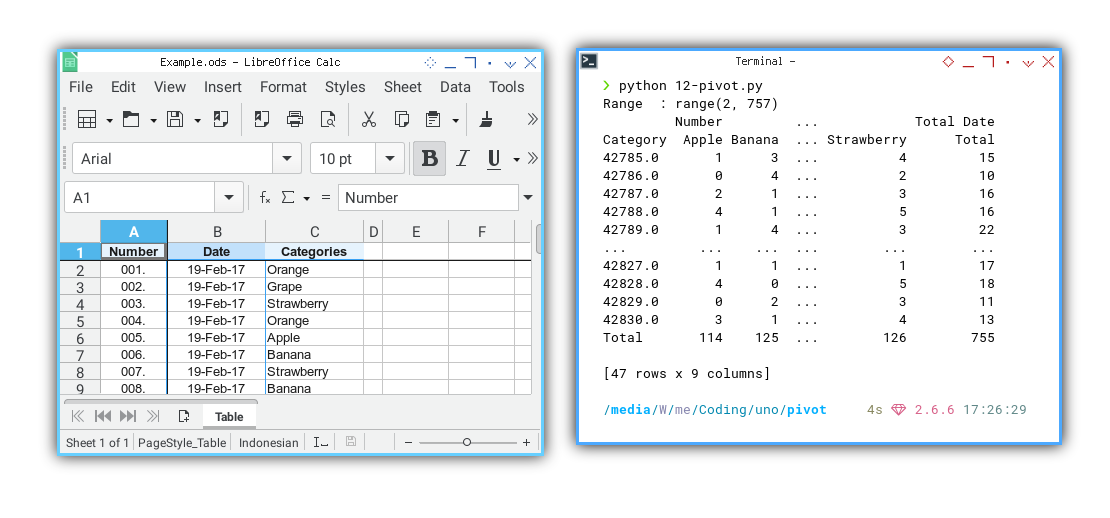
The table source is from the sheet on the left, while the pivot result is displayed in the terminal on the right.
Writer
Now, we move on to filling cells with content from the pivot dataframe.
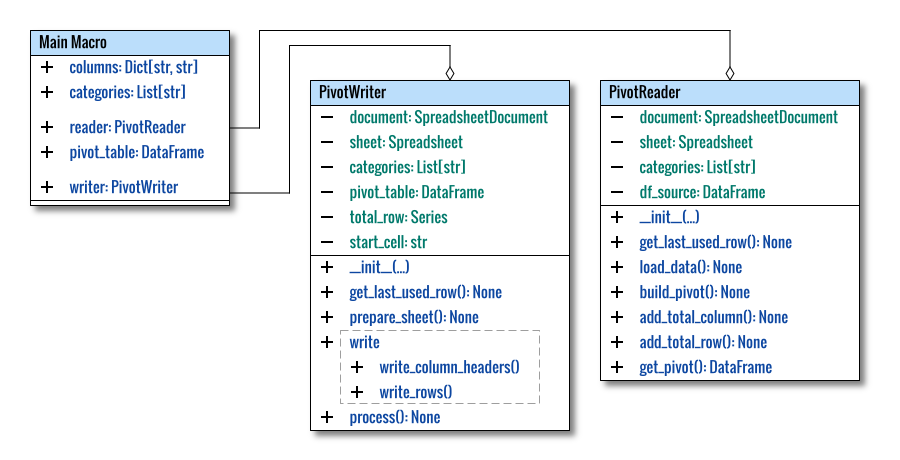
Class Diagram
Here’s the refined diagram:
Directory Structure
.
├── 13-writer.py
└── lib
├── helper.py
├── PivotReader
└── PivotWriter13You can also see the required library in the script below:
Script Skeleton
import pandas as pd
# Local Library
from lib.helper import (
get_desktop, open_document, get_file_path)
from lib.PivotReader import PivotReader
from lib.PivotWriter13 import PivotWriter
def main() -> int:
...
return 0
if __name__ == "__main__":
raise SystemExit(main())
Main
def main() -> int:
columns = {
'index' : 'A',
'date' : 'B',
'cat' : 'C'
}
categories = [
"Apple", "Banana", "Dragon Fruit",
"Durian", "Grape", "Mango",
"Orange", "Strawberry"]
pd.set_option('display.max_rows', 10)
pd.set_option('display.max_columns', 5)
# Getting the source sheet
file_path = get_file_path('Example.ods')
desktop = get_desktop()
document = open_document(desktop, file_path)
if document:
...
return 0
Program Flow
The overall script flow can be described as follows:
if document:
reader = PivotReader(document,
'Table', columns, categories)
pivot_table = reader.get_pivot()
# Print the newly created pivot table
# on terminal console for monitoring
print(pivot_table)
print()
writer = PivotWriter(document,
'Pivot', pivot_table, categories, 'B2')
writer.process()
Class: PivotWriter: Initialization
Similar to PivotReader, for the PivotWriter,
we can also copy-paste our previous Python macro,
and adapt it to a Python UNO script.
The only difference is in the initialization part.
This part is longer,
because we add desktop and document
as parameter argument.
class PivotWriter:
def __init__(self,
document : 'com.sun.star.sheet.SpreadsheetDocument',
sheetName : str,
pivot_table : pd.DataFrame,
categories : List[str],
start_cell : str) -> None:
# save initial parameter
self.document = document
self.sheetName = sheetName
self.pivot_table = pivot_table
self.categories = categories
self.start_cell = start_cell
After obtaining this document, the rest remains the same as the macro example.
# Get the 'Total' row as a separate variable
self.total_row = self.pivot_table.loc['Total']
# Exclude the 'Total' row from the DataFrame
self.pivot_table = self.pivot_table.drop('Total')
Getting the Model
Why do I require the desktop anyway? The reason is that we need the model for various tasks, such as number formatting.
def prepare_sheet(self):
...
# activate sheet
spreadsheetView = self.document.getCurrentController()
spreadsheetView.setActiveSheet(self.sheet)
# number and date format
self.numberfmt = self.document.NumberFormats
self.locale = self.document.CharLocale
self.dateFormat = self.numberfmt. \
getStandardFormat(2, self.locale)
Result Preview
Now, we can observe the result on the sheet.
❯ python 13-writer.py
Range : range(2, 757)
Number ... Total Date
Category Apple Banana ... Strawberry Total
42785.0 1 3 ... 4 15
42786.0 0 4 ... 2 10
42787.0 2 1 ... 3 16
42788.0 4 1 ... 5 16
42789.0 1 4 ... 3 22
... ... ... ... ... ...
42827.0 1 1 ... 1 17
42828.0 4 0 ... 5 18
42829.0 0 2 ... 3 11
42830.0 3 1 ... 4 13
Total 114 125 ... 126 755
[47 rows x 9 columns]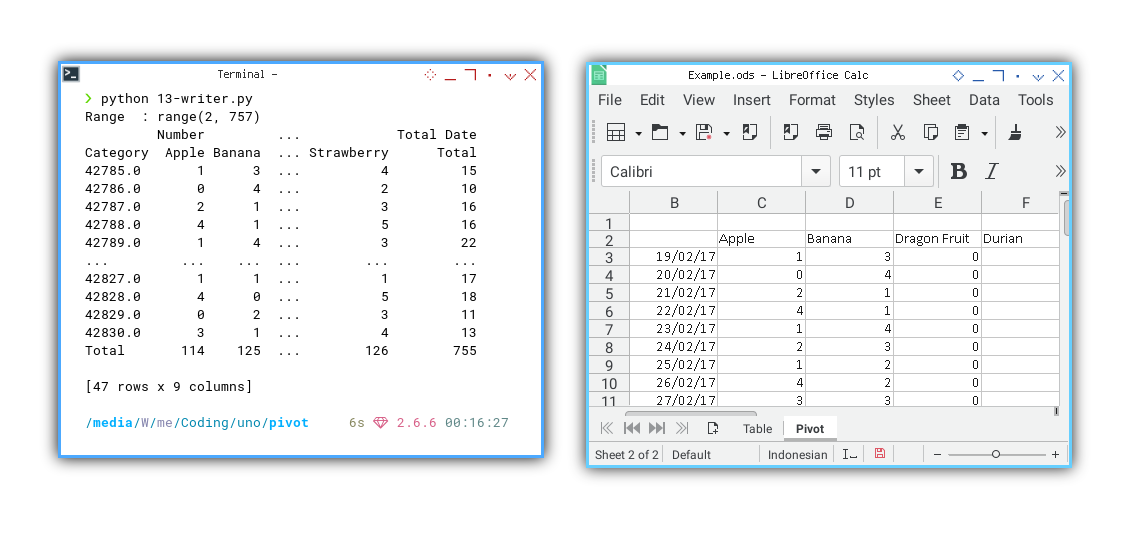
The pivot dataframe source is displayed in the terminal on the left, while the pivot sheet result is showcased in the worksheet on the right.
Decoration
With a little effort, we can transform this plain pivot table into an aesthetically pleasing sheet.
Directory Structure
.
├── 14-deco.py
└── lib
├── helper.py
├── PivotReader
└── PivotWriter14You can also see the required library in the script below:
Script Skeleton
import pandas as pd
# Local Library
from lib.helper import (
get_desktop, open_document, get_file_path)
from lib.PivotReader import PivotReader
from lib.PivotWriter14 import PivotWriter
def main() -> int:
...
return 0
if __name__ == "__main__":
raise SystemExit(main())
Main
The main part remains identical to the previous script. The difference lies in the local class library.
Class: PivotWriter: Initialization
Once again, the initialization is identical to the previous script. However, the rest of the class has been enhanced by copying from its Python macro counterpart.
class PivotWriter:
def __init__(self,
document : 'com.sun.star.sheet.SpreadsheetDocument',
sheetName : str,
pivot_table : pd.DataFrame,
categories : List[str],
start_cell : str) -> None:
# save initial parameter
self.document = document
self.sheetName = sheetName
self.pivot_table = pivot_table
self.categories = categories
self.start_cell = start_cell
...
Result Preview
Although the process remains the same as before, the result now has a polished appearance.
Date : 19/02/2017
Date : 20/02/2017
Date : 21/02/2017
...
...
Date : 03/04/2017
Date : 04/04/2017
Date : 05/04/2017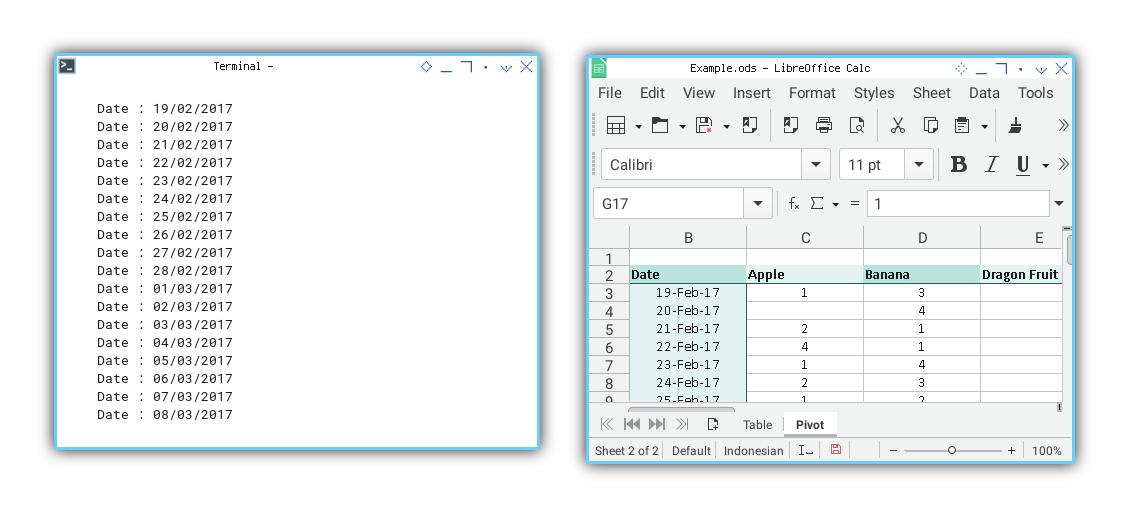
I have also added a date index in the terminal to monitor progress without directly inspecting the worksheet.
Total
In the upcoming section, we are set to incorporate total columns and rows, resulting in a comprehensive pivot table built upon a plain table.
Class Diagram
The complete diagram can be visualized as shown below:
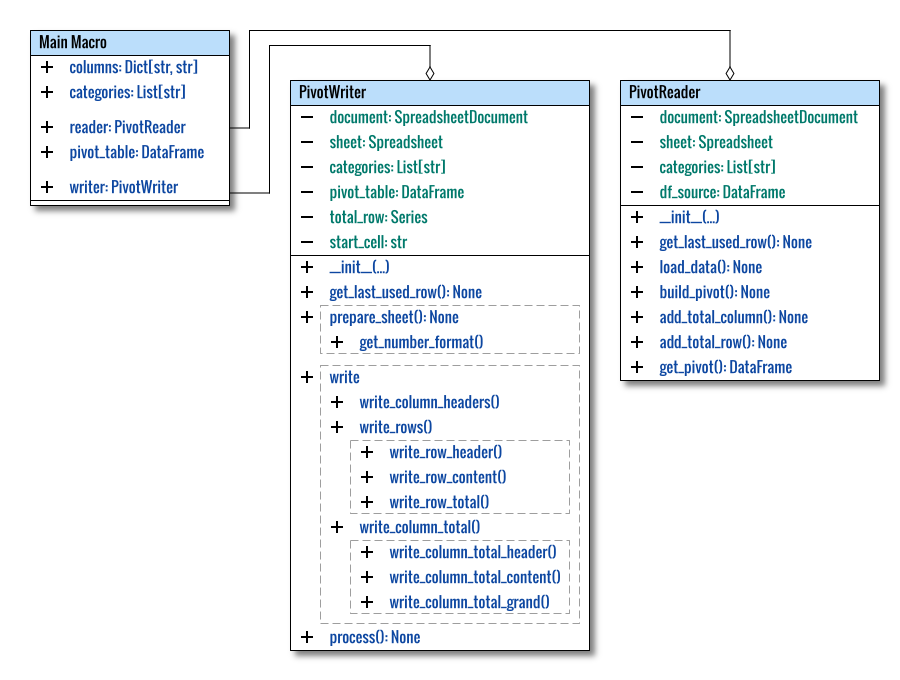
This illustration offers a comprehensive view of the overall structure. I’ve represented the main macro as a class. As is customary, this is a conceptual diagram that requires clarity, hence I’ve opted not to adhere strictly to standard UML diagrams.
Directory Structure
.
├── 15-total.py
└── lib
├── helper.py
├── PivotReader
└── PivotWriterYou can also observe the necessary libraries in the script below:
Script Skeleton
import pandas as pd
# Local Library
from lib.helper import (
get_desktop, open_document, get_file_path)
from lib.PivotReader import PivotReader
from lib.PivotWriter import PivotWriter
def main() -> int:
...
return 0
if __name__ == "__main__":
raise SystemExit(main())
Main
The main portion remains identical to the previous script. The distinction lies in the local class library, which is already well-developed for this project.
Class: PivotWriter: Initialization
Once again, the initialization mirrors the previous script. However, the rest of the class has been refined, utilizing elements copied from its Python macro counterpart.
I won’t reiterate the details here, the class appears to be well-suited for the project. Please refer to the provided source code above for more insights.
Activity Diagram
In summary, the entire process can be visualized in the chronological order depicted below:
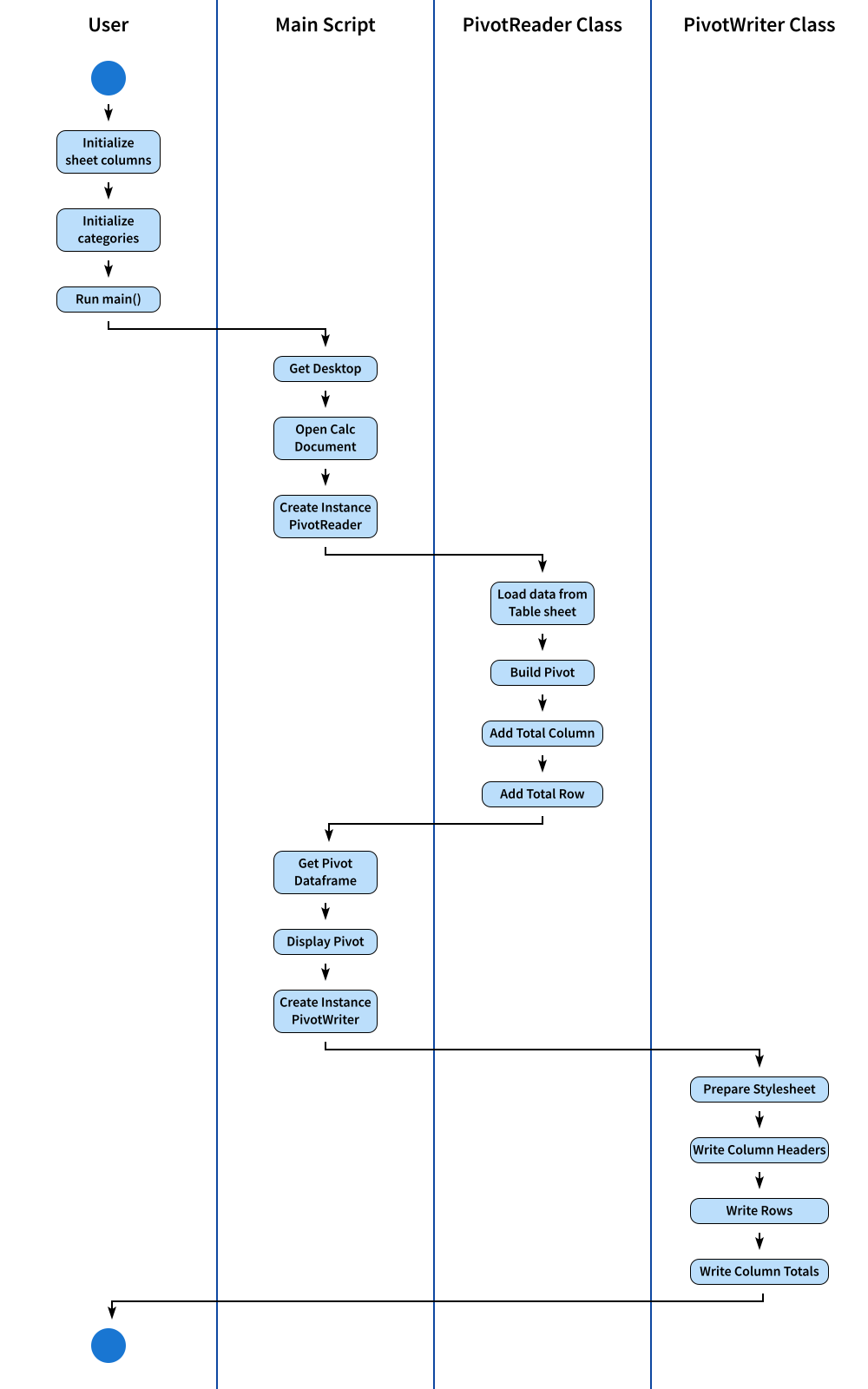
The SVG source is available for modification to suit your needs.
{kind=link}
Result Preview
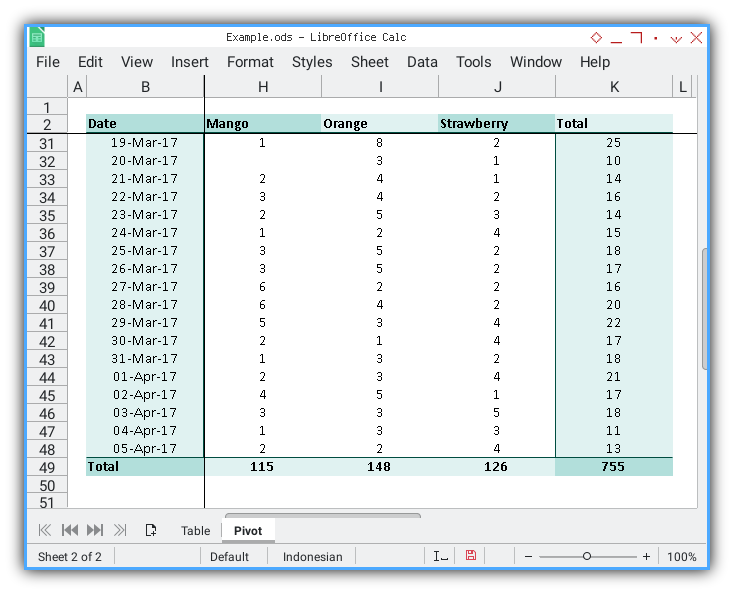
The outcome is an expansive pivot table. I’ve also included freeze panes to allow you to explore the sheet conveniently in a reduced size.
What’s the Next Leg of Our Journey 🤔?
To enrich our experience and directly apply our knowledge to real-life projects, we’ll explore different use cases.
Similar to our macro counterpart
we’ll delve into reading a CSV file
and subsequently writing the results
to both the Table sheet and the Pivot Sheet.
Consider continuing your exploration with [ Pivot - LO UNO - CSV Reader ].