Preface
Goal: Master Detail CSV Reader
-
Using LibreOffice UNO Macro,
-
Using Faktur Pajak (Indonesian Tax) as Example,
-
With Metadata Approach, to avoid too many manual conditional branching.
Local Issue
Indonesia regulation required any VAT (PPn), to be reported using goverment application called ETaxInvoice. This tax application from goverment can be exported into CSV. But this CSV cannot be imported into LibreOffice, because the CSV is a master-detail table relationship.
I also use this case, as an example, of using LibreOffice Macro.
Indonesian Tax
Bagi teman-teman yang butuh untuk meng-export, berkas CSV dari ETAXInvoice (eFaktur), dapat menggunakan script dari artikel ini, untuk di-ubah-pakai sesuai kebutuhan kantor masing-masing.
Script gratis ini hanya contoh, memang tidak sempurna, walaupun begitu cukup untuk kebutuhan sehari-hari.
Related Article
Before you read this article, I suggest you to read these three articles as an introduction.
-
LibreOffice - Decoration Example (prerequisite).
-
Python - Excel - CSV - Part One (prerequisite).
-
Python - Excel - CSV - Part Two (optional).
The first two is a prerequisite, the third one is optional.
The second one contain basic CSV manipulation, in console.
Metadata Approach
To avoid too many hardcoded conditional branch, I keep all setting in metadata as possible.
1: CSV Case: Faktur Keluaran
Consider have a look at this example data.
- Input: faktur-keluaran.csv
This data is simply a double quoted comma separated values. You can see the raw text file as below.
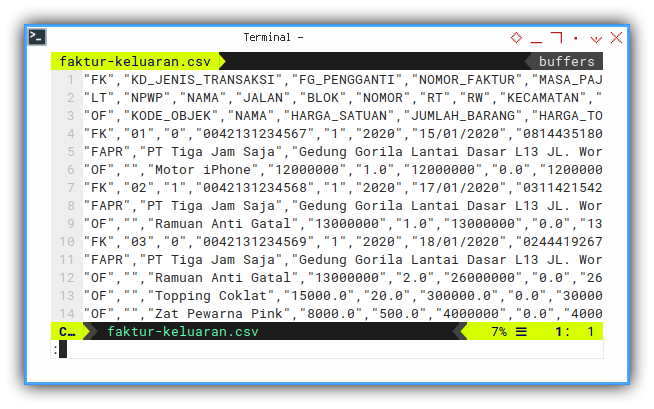
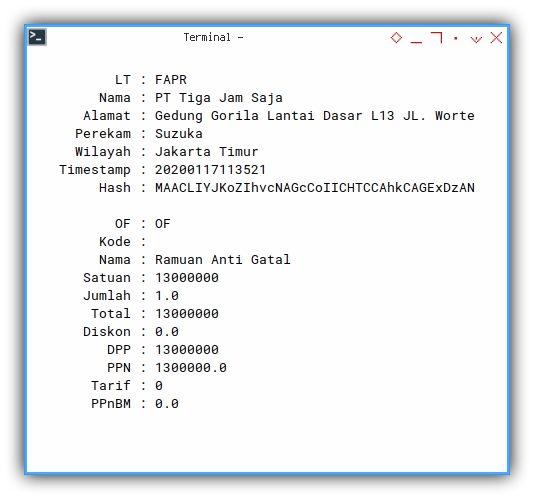
Have a look, one by one. There are at least three distinct content.
- “FK”: This is the master table.
- “FAPR”: This is also one to one relationship with “FK”.
- “OF”: This is clearly a detail table of “FAPR”
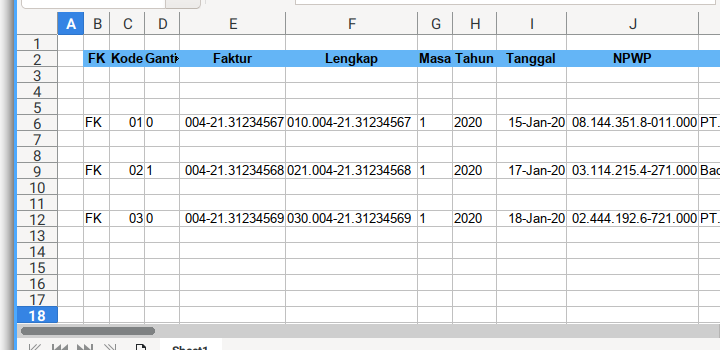
Using Macro, we can achieve multi row master detail in a worksheet. For example this is the master table.
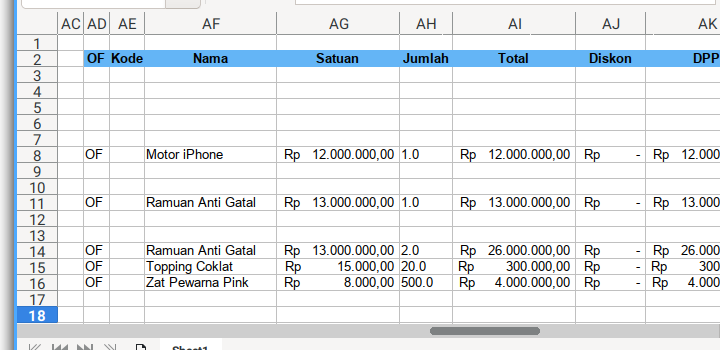
And here below is the detail table, in the same worksheet.
You can execute macro using APSO extension.
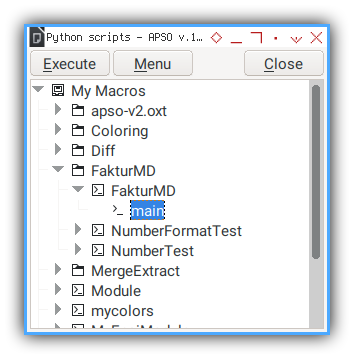
The result can be downloade here:
- Output: sample.ods
2: Master Detail Class
It is a good idea to refactor stuff. Consider the tidier code using OOP below:
Source
This example is about only 276 lines of code.
Skeleton
Consider begin with the big picture.
class FakturSample:
def __init__(self, filename):
def new_sheet(self):
def split_quotes(self, header):
def init_header_keys(self):
def init_field_metadata(self):
def write_header(self, fields):
def set_divider_width(self):
def get_number_format(self, format_string):
def init_format(self):
def date_ordinal(self, value, format_source):
def write_cell(self, cell, metadata, pairs, field_key):
def write_entry(self, row, fields, keys, values):
def process_entry(self, row, line):
def run(self):
def main():We have a bunch of method definition as shown above.
UNO Import
Apart from common import, UNO constant can be accessed using import
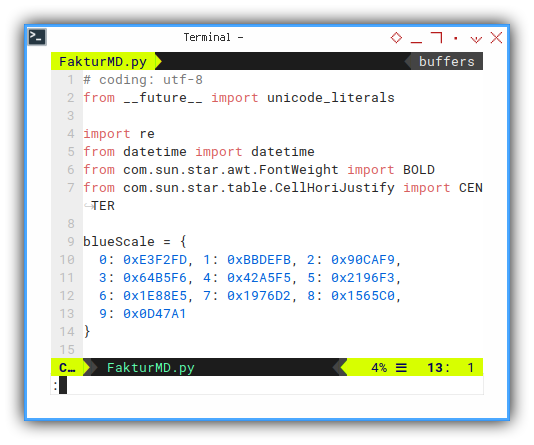
# coding: utf-8
from __future__ import unicode_literals
import re
from datetime import datetime
from com.sun.star.awt.FontWeight import BOLD
from com.sun.star.table.CellHoriJustify import CENTERI also put, material color value, to be used later as cell background.
blueScale = {
0: 0xE3F2FD, 1: 0xBBDEFB, 2: 0x90CAF9,
3: 0x64B5F6, 4: 0x42A5F5, 5: 0x2196F3,
6: 0x1E88E5, 7: 0x1976D2, 8: 0x1565C0,
9: 0x0D47A1
}Here, we import bold and center.
Class Initialization
This is a common part of loading a new blank worksheet.
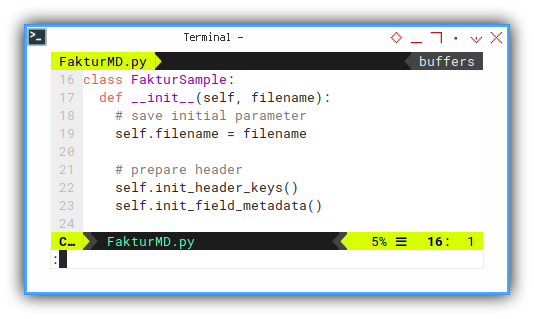
class FakturSample:
def __init__(self, filename):
# save initial parameter
self.filename = filename
# prepare header
self.init_header_keys()
self.init_field_metadata()Nothing special here.
Main Program
The main program execution is just making class instance as below:
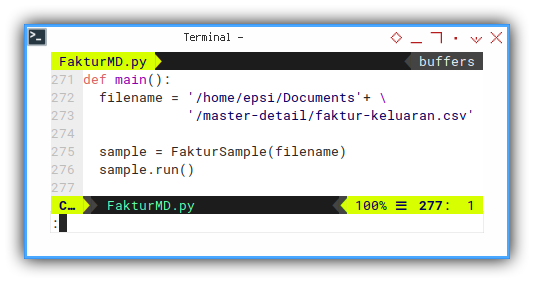
def main():
filename = '/home/epsi/Documents'+ \
'/master-detail/faktur-keluaran.csv'
sample = FakturSample(filename)
sample.run()You can put, your source csv in your own home directory. Or anywhere else to suit your need. Then update the path above.
Execute The Process
The whole process run step by step this run function.
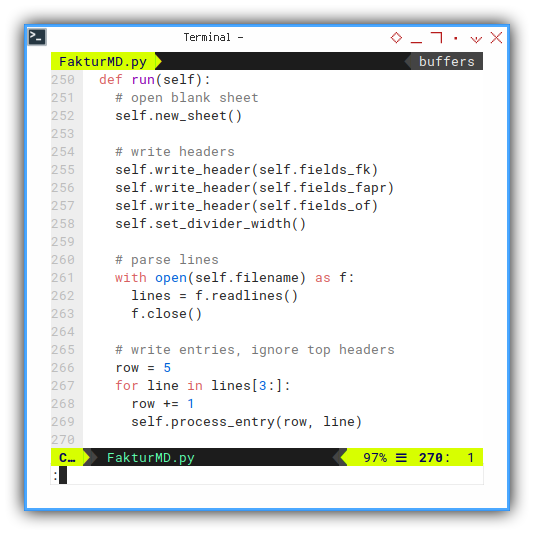
def run(self):
# open blank sheet
self.new_sheet()
# write headers
self.write_header(self.fields_fk)
self.write_header(self.fields_fapr)
self.write_header(self.fields_of)
self.set_divider_width()
# parse lines
with open(self.filename) as f:
lines = f.readlines()
f.close()
# write entries, ignore top headers
row = 5
for line in lines[3:]:
row += 1
self.process_entry(row, line)Generally this is the step:
- Open New Sheet
- Write Headers
- Write Entries using Loop
New Blank Sheet
All begin with blank sheet.
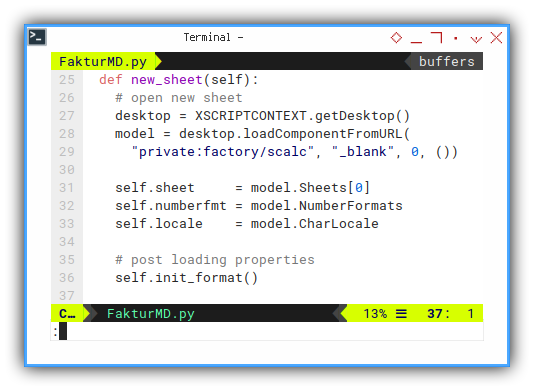
def new_sheet(self):
# open new sheet
desktop = XSCRIPTCONTEXT.getDesktop()
model = desktop.loadComponentFromURL(
"private:factory/scalc", "_blank", 0, ())
self.sheet = model.Sheets[0]
self.numberfmt = model.NumberFormats
self.locale = model.CharLocale
# post loading properties
self.init_format()Number format and locale can only be set, after creating a new blank sheet.
Helper: Split Quotes
Now we begin need to extract the CSV, using regular expression.
And also replace few things, to fix a few bugs, related to the csv source.
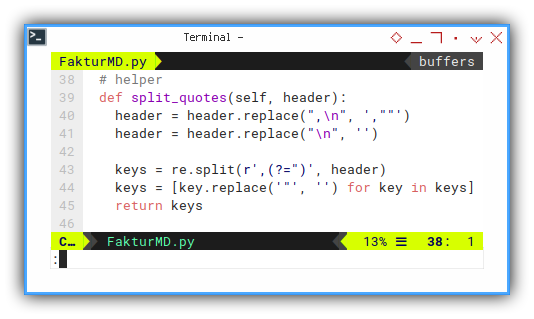
def split_quotes(self, header):
header = header.replace(",\n", ',""')
header = header.replace("\n", '')
keys = re.split(r',(?=")', header)
keys = [key.replace('"', '') for key in keys]
return keysExtract Header Field
I need to have verbatim copy from the government standard
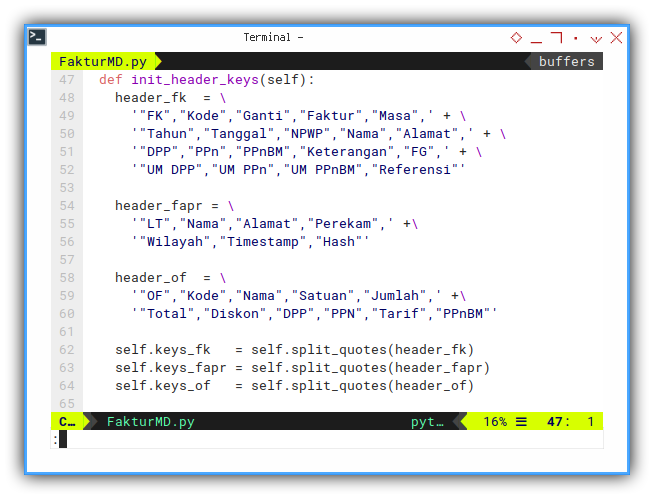
This part is a copy-and-paste the column header definition.
def init_header_keys(self):
header_fk = \
'"FK","Kode","Ganti","Faktur","Masa",' + \
'"Tahun","Tanggal","NPWP","Nama","Alamat",' + \
'"DPP","PPn","PPnBM","Keterangan","FG",' + \
'"UM DPP","UM PPn","UM PPnBM","Referensi"'
header_fapr = \
'"LT","Nama","Alamat","Perekam",' +\
'"Wilayah","Timestamp","Hash"'
header_of = \
'"OF","Kode","Nama","Satuan","Jumlah",' +\
'"Total","Diskon","DPP","PPN","Tarif","PPnBM"'And also extract the copy above, and make these keys internal properties of the class
self.keys_fk = self.split_quotes(header_fk)
self.keys_fapr = self.split_quotes(header_fapr)
self.keys_of = self.split_quotes(header_of)Consider see the result, so you can imagine how it is going to be.
Field Metadata
The main advantage.
To keep all field tidy, I put all setting in metadata as possible.
You can make your own custom metadata template freely
The metadata control these:
- Column Position (Cell Letter)
- Column Width
- Cell Data Type
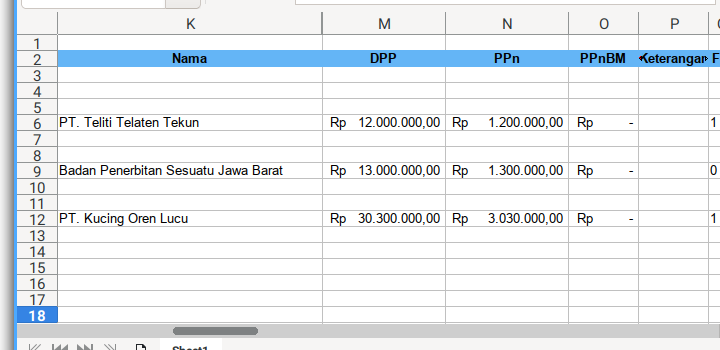
This is the master table
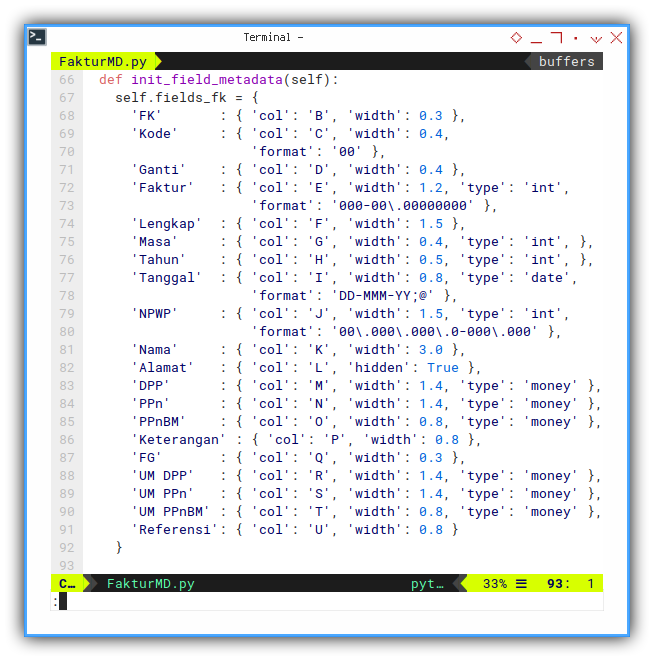
def init_field_metadata(self):
self.fields_fk = {
'FK' : { 'col': 'B', 'width': 0.3 },
'Kode' : { 'col': 'C', 'width': 0.4,
'format': '00' },
'Ganti' : { 'col': 'D', 'width': 0.4 },
'Faktur' : { 'col': 'E', 'width': 1.2, 'type': 'int',
'format': '000-00\.00000000' },
'Lengkap' : { 'col': 'F', 'width': 1.5 },
'Masa' : { 'col': 'G', 'width': 0.4, 'type': 'int', },
'Tahun' : { 'col': 'H', 'width': 0.5, 'type': 'int', },
'Tanggal' : { 'col': 'I', 'width': 0.8, 'type': 'date',
'format': 'DD-MMM-YY;@' },
'NPWP' : { 'col': 'J', 'width': 1.5, 'type': 'int',
'format': '00\.000\.000\.0-000\.000' },
'Nama' : { 'col': 'K', 'width': 3.0 },
'Alamat' : { 'col': 'L', 'hidden': True },
'DPP' : { 'col': 'M', 'width': 1.4, 'type': 'money' },
'PPn' : { 'col': 'N', 'width': 1.4, 'type': 'money' },
'PPnBM' : { 'col': 'O', 'width': 0.8, 'type': 'money' },
'Keterangan' : { 'col': 'P', 'width': 0.8 },
'FG' : { 'col': 'Q', 'width': 0.3 },
'UM DPP' : { 'col': 'R', 'width': 1.4, 'type': 'money' },
'UM PPn' : { 'col': 'S', 'width': 1.4, 'type': 'money' },
'UM PPnBM' : { 'col': 'T', 'width': 0.8, 'type': 'money' },
'Referensi': { 'col': 'U', 'width': 0.8 }
}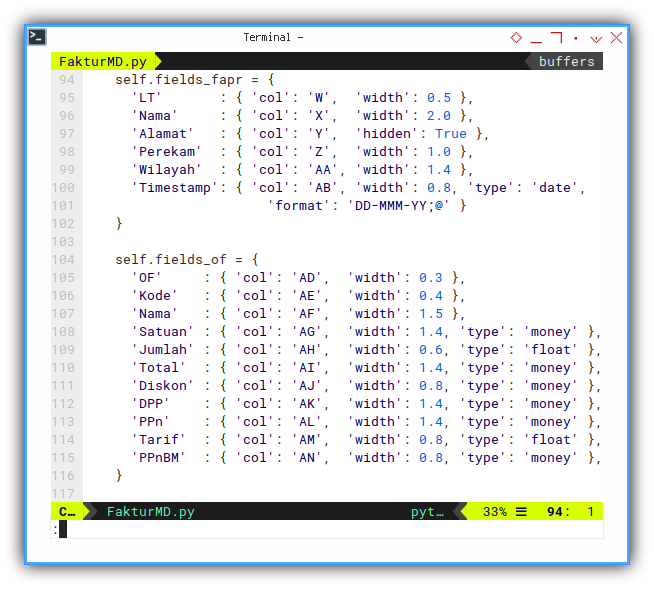
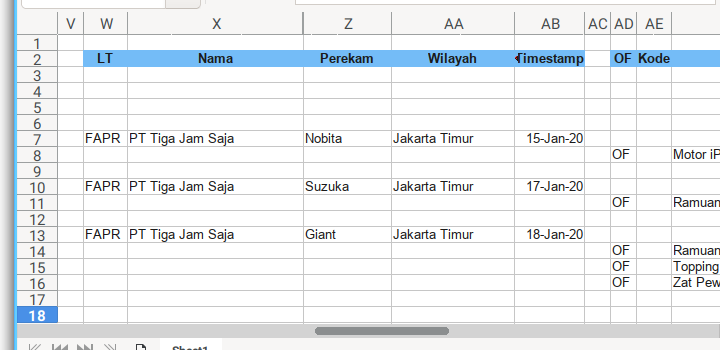
The one to one relationship.
self.fields_fapr = {
'LT' : { 'col': 'W', 'width': 0.5 },
'Nama' : { 'col': 'X', 'width': 2.0 },
'Alamat' : { 'col': 'Y', 'hidden': True },
'Perekam' : { 'col': 'Z', 'width': 1.0 },
'Wilayah' : { 'col': 'AA', 'width': 1.4 },
'Timestamp': { 'col': 'AB', 'width': 0.8, 'type': 'date',
'format': 'DD-MMM-YY;@' }
}And the detail table.
self.fields_of = {
'OF' : { 'col': 'AD', 'width': 0.3 },
'Kode' : { 'col': 'AE', 'width': 0.4 },
'Nama' : { 'col': 'AF', 'width': 1.5 },
'Satuan' : { 'col': 'AG', 'width': 1.4, 'type': 'money' },
'Jumlah' : { 'col': 'AH', 'width': 0.6, 'type': 'float' },
'Total' : { 'col': 'AI', 'width': 1.4, 'type': 'money' },
'Diskon' : { 'col': 'AJ', 'width': 0.8, 'type': 'money' },
'DPP' : { 'col': 'AK', 'width': 1.4, 'type': 'money' },
'PPn' : { 'col': 'AL', 'width': 1.4, 'type': 'money' },
'Tarif' : { 'col': 'AM', 'width': 0.8, 'type': 'float' },
'PPnBM' : { 'col': 'AN', 'width': 0.8, 'type': 'money' },
}Writing Header to Sheet
Luckily we can make a generic method, for three headers “FK”, “FAPR”, or “OF”.
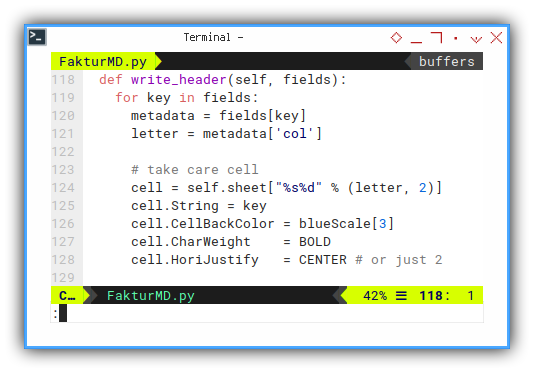
It is a matter of decorating the cell.
def write_header(self, fields):
for key in fields:
metadata = fields[key]
letter = metadata['col']
# take care cell
cell = self.sheet["%s%d" % (letter, 2)]
cell.String = key
cell.CellBackColor = blueScale[3]
cell.CharWeight = BOLD
cell.HoriJustify = CENTER # or just 2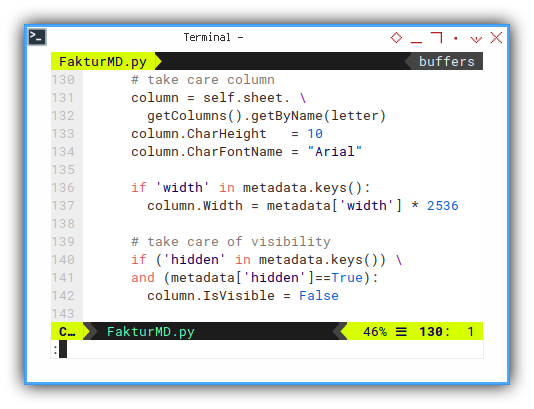
And do not forget the width and visibility.
# take care column
column = self.sheet. \
getColumns().getByName(letter)
column.CharHeight = 10
column.CharFontName = "Arial"
if 'width' in metadata.keys():
column.Width = metadata['width'] * 2536
# take care of visibility
if ('hidden' in metadata.keys()) \
and (metadata['hidden']==True):
column.IsVisible = FalseDivider Width
There might be something else not set in metadata.
We should set manually.
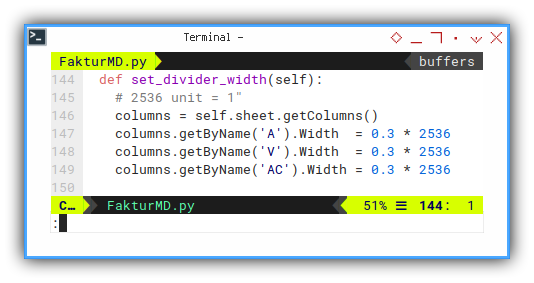
def set_divider_width(self):
# 2536 unit = 1"
columns = self.sheet.getColumns()
columns.getByName('A').Width = 0.3 * 2536
columns.getByName('V').Width = 0.3 * 2536
columns.getByName('AC').Width = 0.3 * 2536I’m not sure the unit used in LibreOffice.
I think it is about 100 mm.
And I like to set up my LO in inch unit.
So I end up with 2536 conversion number.
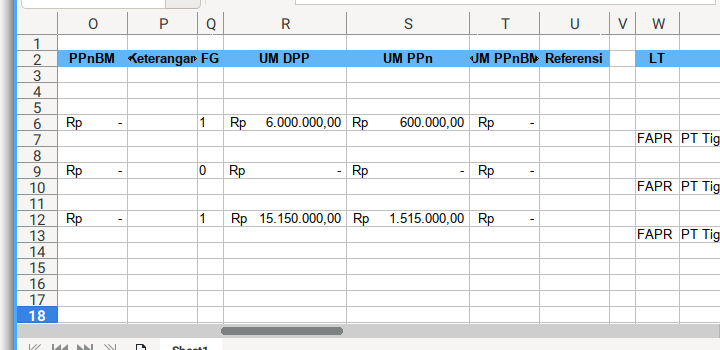
Consider see the preview here:
Helper: Number Format
Since we cannot just set numberFormat. We have to add the format string to LO index first, then assign the index to the cell.
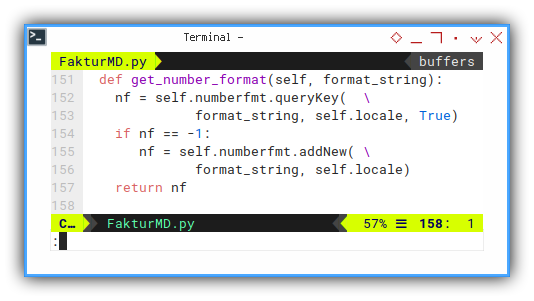
nf = self.numberfmt.queryKey( \
format_string, self.locale, True)
if nf == -1:
nf = self.numberfmt.addNew( \
format_string, self.locale)
return nfInitialize Formatting String
There are two recurring format,
- The
moneytype and - The
datetype.
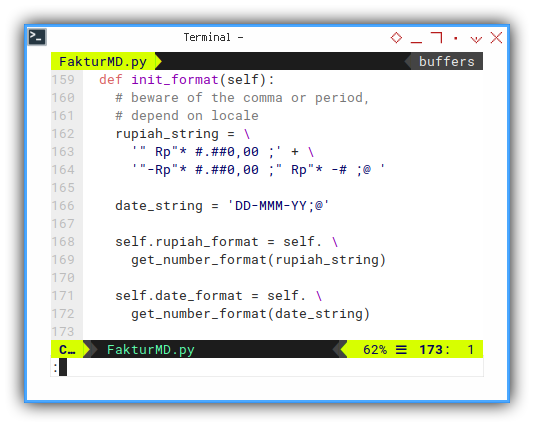
def init_format(self):
# beware of the comma or period,
# depend on locale
rupiah_string = \
'" Rp"* #.##0,00 ;' + \
'"-Rp"* #.##0,00 ;" Rp"* -# ;@ '
date_string = 'DD-MMM-YY;@'
self.rupiah_format = self. \
get_number_format(rupiah_string)
self.date_format = self. \
get_number_format(date_string)- The Currency in Rupiah
'" Rp"* #.##0,00 ;"-Rp"* #.##0,00 ;" Rp"* -# ;@'- The Date, using my favorite format
'DD-MMM-YY;@'Helper: Storing Date Value Programatically
We can make helper to have the value of the date. To be stored later in a cell in a worksheet.
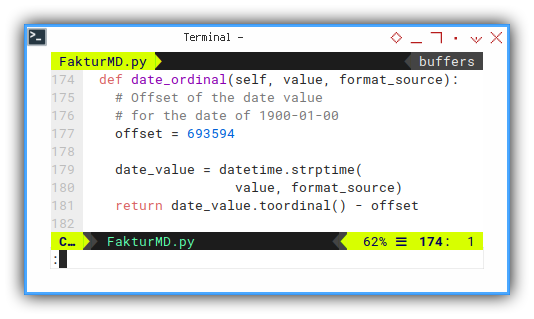
def date_ordinal(self, value, format_source):
# Offset of the date value
# for the date of 1900-01-00
offset = 693594
date_value = datetime.strptime(
value, format_source)
return date_value.toordinal() - offsetWriting Content to Cell
The main purpose is to put the right value to the cell, based on metadata, and also put the right format based on metadata.
But this could be tricky, for special case, such as date, that has different date format from the source. One timestamp, and the other is ordinary date.
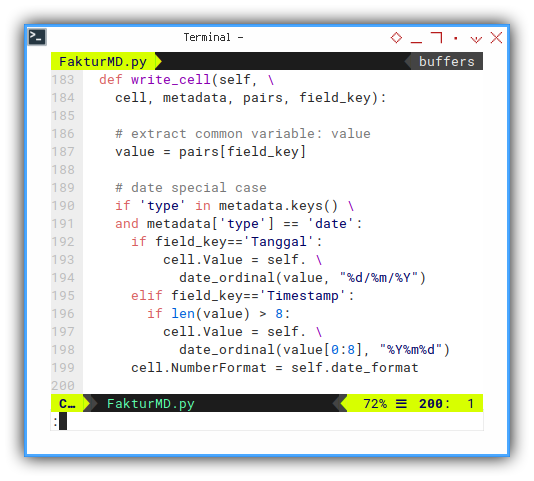
def write_cell(self, \
cell, metadata, pairs, field_key):
# extract common variable: value
value = pairs[field_key]
# date special case
if 'type' in metadata.keys() \
and metadata['type'] == 'date':
if field_key=='Tanggal':
cell.Value = self. \
date_ordinal(value, "%d/%m/%Y")
elif field_key=='Timestamp':
if len(value) > 8:
cell.Value = self. \
date_ordinal(value[0:8], "%Y%m%d")
cell.NumberFormat = self.date_format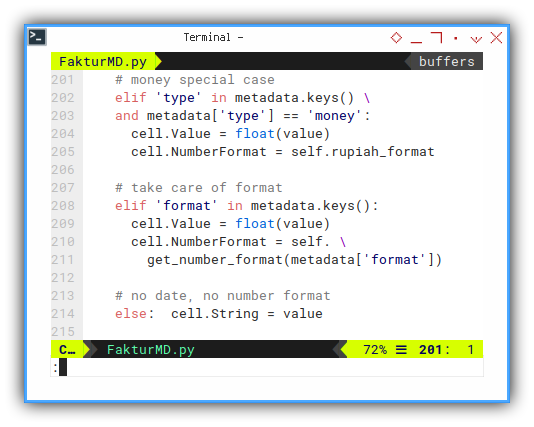
The rest is easy. Just put the format according to metadata setting.
# money special case
elif 'type' in metadata.keys() \
and metadata['type'] == 'money':
cell.Value = float(value)
cell.NumberFormat = self.rupiah_format
# take care of format
elif 'format' in metadata.keys():
cell.Value = float(value)
cell.NumberFormat = self. \
get_number_format(metadata['format'])
# no date, no number format
else: cell.String = valueWriting Each Line of Entry
This function extract the medatada and value.
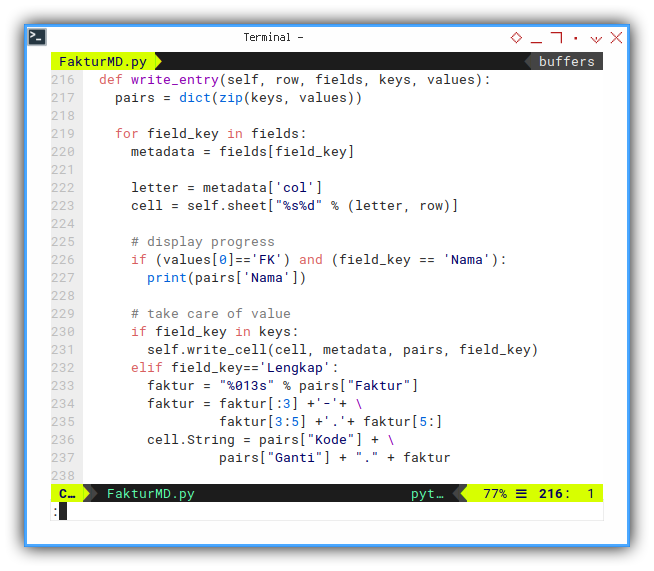
def write_entry(self, row, fields, keys, values):
pairs = dict(zip(keys, values))
for field_key in fields:
metadata = fields[field_key]
letter = metadata['col']
cell = self.sheet["%s%d" % (letter, row)]We can additionaly display progress to the console.
# display progress
if (values[0]=='FK') and (field_key == 'Nama'):
print(pairs['Nama'])And write each cell.
# take care of value
if field_key in keys:
self.write_cell(cell, metadata, pairs, field_key)
elif field_key=='Lengkap':
faktur = "%013s" % pairs["Faktur"]
faktur = faktur[:3] +'-'+ \
faktur[3:5] +'.'+ faktur[5:]
cell.String = pairs["Kode"] + \
pairs["Ganti"] + "." + fakturThe only special case is, a field called ‘Lengkap’. This means complete serial number of the tax code. Such as:
010.004-21.31234567This Lengkap field is a generated field content.
again, we can see the preview as below:
Process Each Entry Line
We need to write three headers, based on the signature: “FK”, “FAPR”, or “OF”.
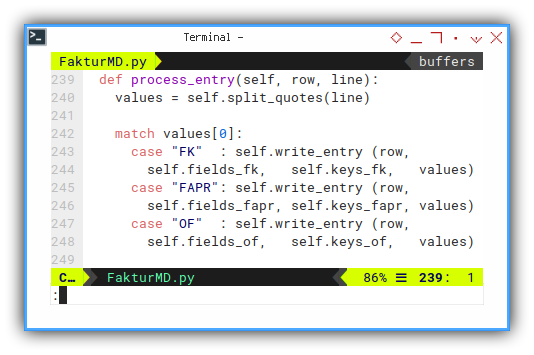
def process_entry(self, row, line):
values = self.split_quotes(line)
match values[0]:
case "FK" : self.write_entry (row,
self.fields_fk, self.keys_fk, values)
case "FAPR": self.write_entry (row,
self.fields_fapr, self.keys_fapr, values)
case "OF" : self.write_entry (row,
self.fields_of, self.keys_of, values)Let me remind the signature: “FK”, “FAPR”, or “OF”, from CSV source here:
All function definition has been explained here.
It is a good time to test the result!
Summary
As a summary, here is what this script do.
-
Using LibreOffice UNO Macro,
-
Using Faktur Pajak (Indonesian Tax) as Example,
-
With Metadata Approach, to avoid too many manual conditional branching.
Sheet Result
How about the output?
Consider to open the sample.ods spreadsheet.
- Output: sample.ods
This is going to be very wide sheet. So I took five screenshots.
I think that’s all.
What is Next 🤔?
Still about tax, I have a cool trick to transform plain row based data into cute form view.
Consider continue reading [ LibreOffice - Macro - Copy Range ].