Preface
Goal: Master Detail CSV Reader, Using OpenPyXL
Using Faktur Pajak (Indonesian Tax) as Example.
There will be a lot of picture here. But the code is actually simple.
And still, there is not much paragraph either.
1: Writing Master Header
Export to Spreadsheet.
It is time to use openpyxl.
Source
Just an OOP version modification of previous code.
Skeleton
All definition shown here:
import ...
def split_quotes(header):
class FakturMD2Sheet:
def __init__(self, sheet):
def init_header_keys(self):
def init_sheet_style(self):
def set_column_width(self):
def write_header(self):
def run(self):
def main():
main()Import
We need a few import statement.
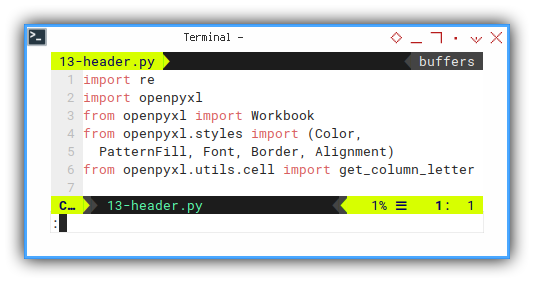
import re
import openpyxl
from openpyxl import Workbook
from openpyxl.styles import (Color,
PatternFill, Font, Border, Alignment)
from openpyxl.utils.cell import get_column_letterHelper: Split Quotes
And also fix comma bug at the end of the “FK” row entries.
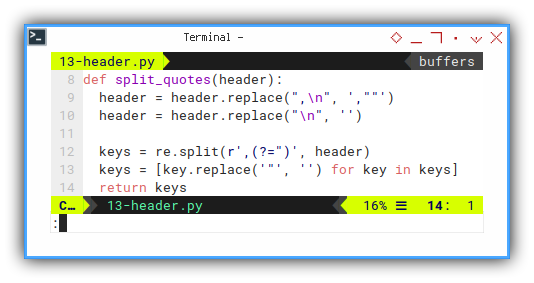
def split_quotes(header):
header = header.replace(",\n", ',""')
header = header.replace("\n", '')
keys = re.split(r',(?=")', header)
keys = [key.replace('"', '') for key in keys]
return keysClass Initialization
We can start all in initialization.
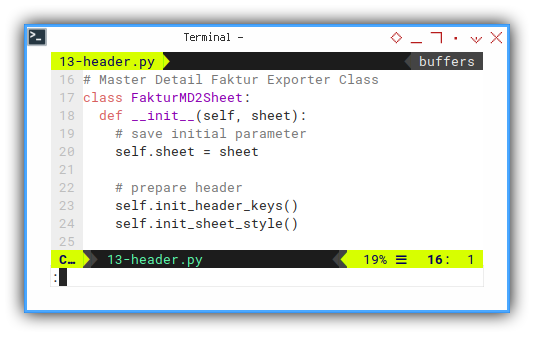
# Master Detail Faktur Exporter Class
class FakturMD2Sheet:
def __init__(self, sheet):
# save initial parameter
self.sheet = sheet
# prepare header
self.init_header_keys()
self.init_sheet_style()Header Keys
And as usual, put header name definition in its own function.
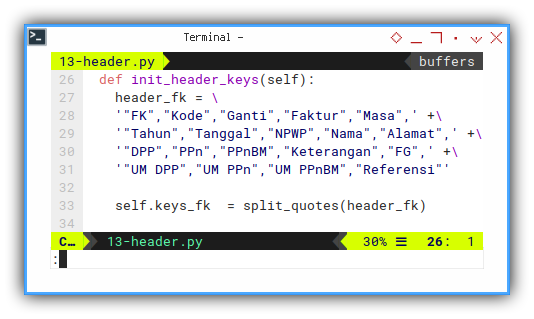
def init_header_keys(self):
header_fk = \
'"FK","Kode","Ganti","Faktur","Masa",' +\
'"Tahun","Tanggal","NPWP","Nama","Alamat",' +\
'"DPP","PPn","PPnBM","Keterangan","FG",' +\
'"UM DPP","UM PPn","UM PPnBM","Referensi"'
self.keys_fk = split_quotes(header_fk)Style
A method to set required style.
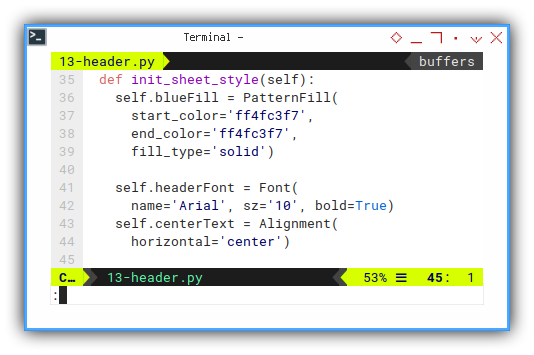
def init_sheet_style(self):
self.blueFill = PatternFill(
start_color='ff4fc3f7',
end_color='ff4fc3f7',
fill_type='solid')
self.headerFont = Font(name='Arial', sz='10', bold=True)
self.centerText = Alignment(horizontal='center')Column Width
Displayed column width can make a difference.
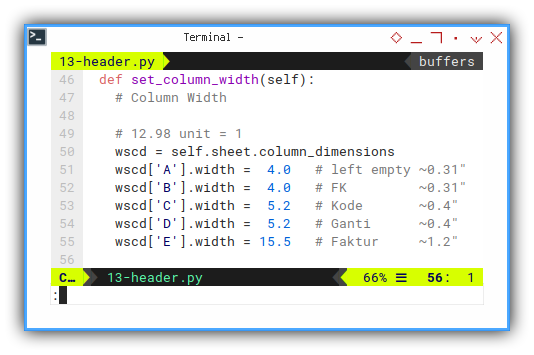
def set_column_width(self):
# Column Width
# 12.98 unit = 1
wscd = self.sheet.column_dimensions
wscd['A'].width = 4.0 # left empty ~0.31"
wscd['B'].width = 4.0 # FK ~0.31"
wscd['C'].width = 5.2 # Kode ~0.4"
wscd['D'].width = 5.2 # Ganti ~0.4"
wscd['E'].width = 15.5 # Faktur ~1.2"Header Cell
Now we can iterate the header keys, and write each cell header name, followed by its style.
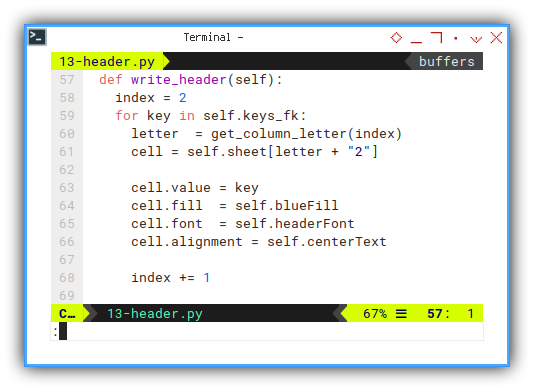
def write_header(self):
index = 2
for key in self.keys_fk:
letter = get_column_letter(index)
cell = self.sheet[letter + "2"]
cell.value = key
cell.fill = self.blueFill
cell.font = self.headerFont
cell.alignment = self.centerText
index += 1Run: Write, and Decorate
Gather all the function, execute the process.
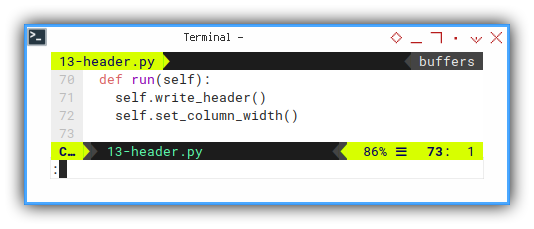
def run(self):
self.write_header()
self.set_column_width()Main
And finally make a class instance in main function.
def main():
wb = Workbook()
ws = wb.active
md = FakturMD2Sheet(ws)
md.run()
# Save the file
wb.save("sample.xlsx")
main()Result
There is nothing to display in output.
Because all written in sheet.
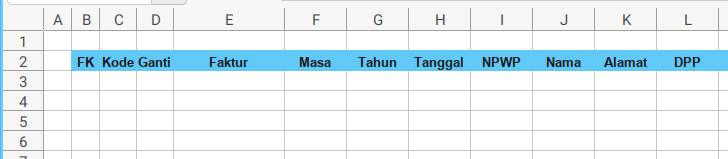
Sheet Result
Consider to open the sample.xlsx spreadheet.
2: Field Metadata
Defining Each Field Property
We jump to a more systematic approach with metadata, as based structure of each column.
Source
Just an OOP version modification of previous code.
Skeleton
All definition shown here:
import ...
def split_quotes(header):
class FakturMD2Sheet:
def __init__(self, filename, sheet):
def init_header_keys(self):
def init_field_metadata(self):
def init_sheet_style(self):
def write_header(self, fields):
def run(self):
def main():
main()Import
We need just one additional line.
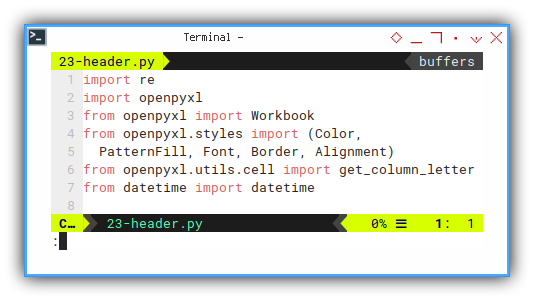
# ...
from datetime import datetimeClass Initialization
We can start all in initialization.
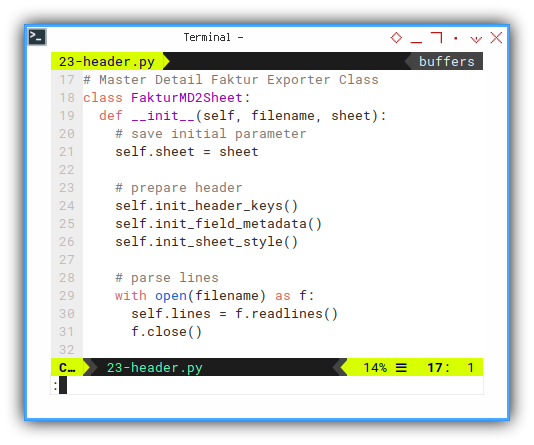
# Master Detail Faktur Exporter Class
class FakturMD2Sheet:
def __init__(self, filename, sheet):
# save initial parameter
self.sheet = sheet
# prepare header
self.init_header_keys()
self.init_field_metadata()
self.init_sheet_style()
# parse lines
with open(filename) as f:
self.lines = f.readlines()
f.close()Simple Metadata
Consider this field metadata:
- Column Position (Cell Letter)
- Column Width
- Cell Data Type
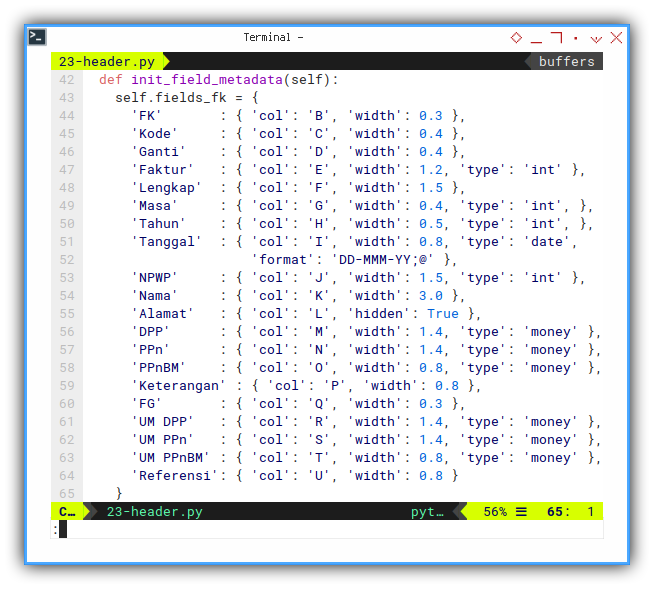
def init_field_metadata(self):
self.fields_fk = {
'FK' : { 'col': 'B', 'width': 0.3 },
'Kode' : { 'col': 'C', 'width': 0.4 },
'Ganti' : { 'col': 'D', 'width': 0.4 },
'Faktur' : { 'col': 'E', 'width': 1.2, 'type': 'int' },
'Lengkap' : { 'col': 'F', 'width': 1.5 },
'Masa' : { 'col': 'G', 'width': 0.4, 'type': 'int', },
'Tahun' : { 'col': 'H', 'width': 0.5, 'type': 'int', },
'Tanggal' : { 'col': 'I', 'width': 0.8, 'type': 'date',
'format': 'DD-MMM-YY;@' },
'NPWP' : { 'col': 'J', 'width': 1.5, 'type': 'int' },
'Nama' : { 'col': 'K', 'width': 3.0 },
'Alamat' : { 'col': 'L', 'hidden': True },
'DPP' : { 'col': 'M', 'width': 1.4, 'type': 'money' },
'PPn' : { 'col': 'N', 'width': 1.4, 'type': 'money' },
'PPnBM' : { 'col': 'O', 'width': 0.8, 'type': 'money' },
'Keterangan' : { 'col': 'P', 'width': 0.8 },
'FG' : { 'col': 'Q', 'width': 0.3 },
'UM DPP' : { 'col': 'R', 'width': 1.4, 'type': 'money' },
'UM PPn' : { 'col': 'S', 'width': 1.4, 'type': 'money' },
'UM PPnBM' : { 'col': 'T', 'width': 0.8, 'type': 'money' },
'Referensi': { 'col': 'U', 'width': 0.8 }
}Style
Also, just one additional line.
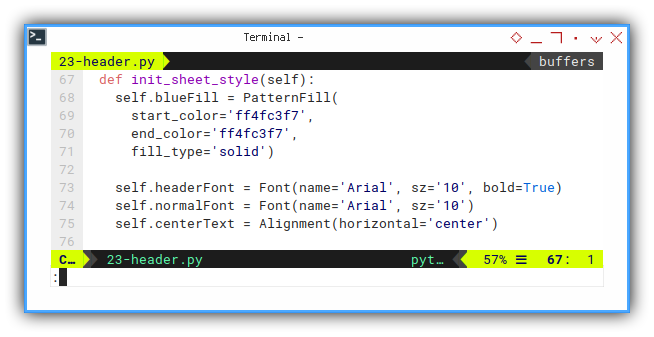
self.centerText = Alignment(horizontal='center')Cell Header
Now we can iterate the header keys, and write each cell header name, followed by its style. All based on respective field metadata.
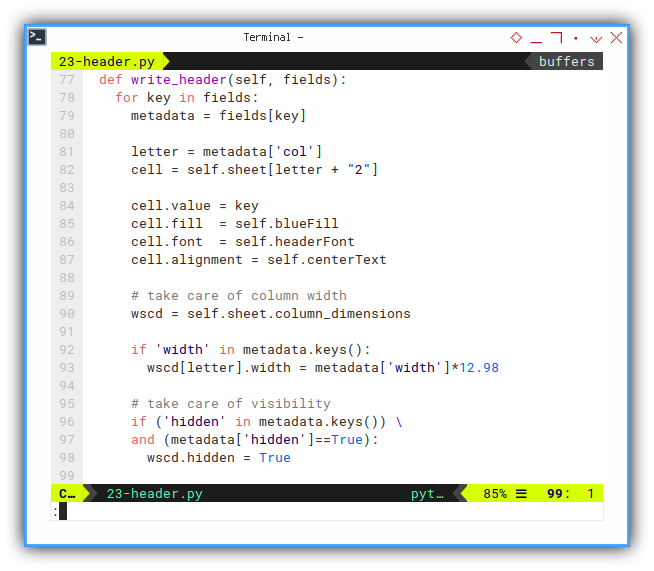
def write_header(self, fields):
for key in fields:
metadata = fields[key]
letter = metadata['col']
cell = self.sheet[letter + "2"]
cell.value = key
cell.fill = self.blueFill
cell.font = self.headerFont
cell.alignment = self.centerTextDo not forget the width and visibility.
# take care of column width
wscd = self.sheet.column_dimensions
if 'width' in metadata.keys():
wscd[letter].width = metadata['width']*12.98
# take care of visibility
if ('hidden' in metadata.keys()) \
and (metadata['hidden']==True):
wscd.hidden = TrueRun: Write, and Decorate
Now the code is even shorter.
def run(self):
# write headers
self.write_header(self.fields_fk)Main
And finally make a class instance in main function.
def main():
filename = 'faktur-keluaran.csv'
wb = Workbook()
ws = wb.active
md = FakturMD2Sheet(filename, ws)
md.run()
# Save the file
wb.save("sample.xlsx")
main()Result
There is nothing to display in output. Because all written in sheet.
Sheet Result
Consider to open the sample.xlsx spreadsheet. This is going to be very wide sheet. So I took three screenshots.
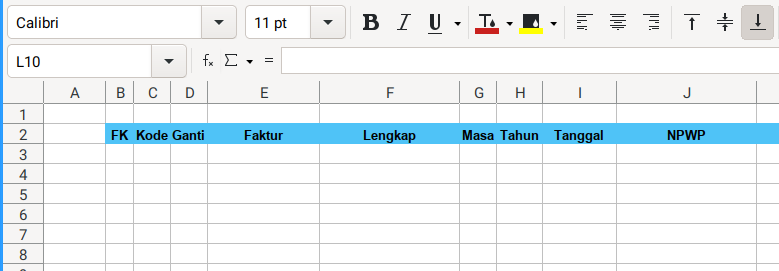
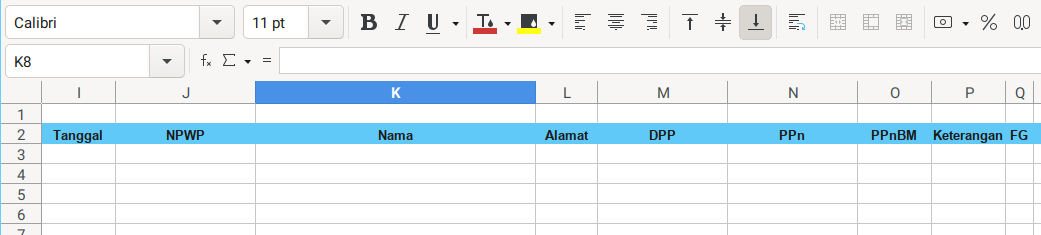
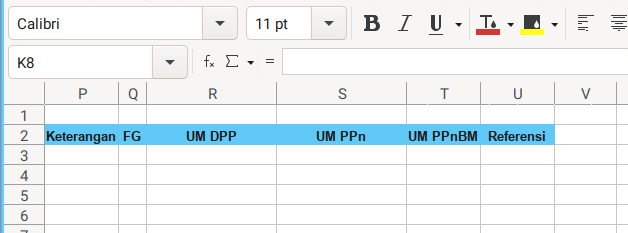
3: Writing Entries
Process Master Entries
This is the same with previous code, but with entries.
Source
Just an OOP version modification of previous code.
Class Initialization
The same with previous. But with filename, so we can parse each lines later.
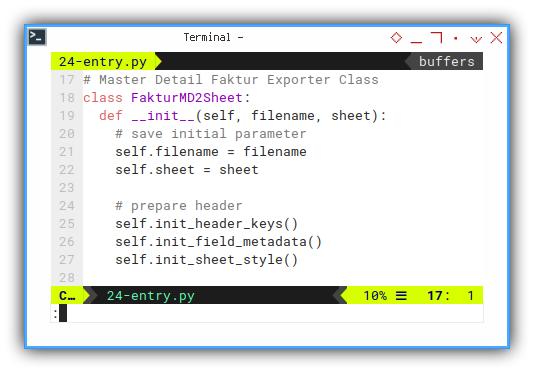
# Master Detail Faktur Exporter Class
class FakturMD2Sheet:
def __init__(self, filename, sheet):
# save initial parameter
self.filename = filename
self.sheet = sheet
# prepare header
self.init_header_keys()
self.init_field_metadata()
self.init_sheet_style()Cell Content
Just like header, we can can iterate the content, and write each cell value. All based on type, defined in field metadata.
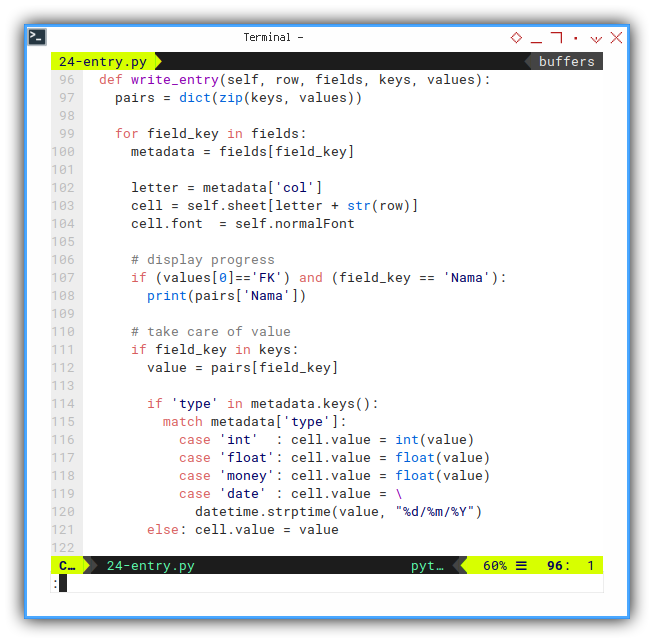
def write_entry(self, row, fields, keys, values):
pairs = dict(zip(keys, values))
for field_key in fields:
metadata = fields[field_key]
letter = metadata['col']
cell = self.sheet[letter + str(row)]
cell.font = self.normalFontWe can display the progress to the console.
# display progress
if (values[0]=='FK') and (field_key == 'Nama'):
print(pairs['Nama'])And take care of the value.
# take care of value
if field_key in keys:
value = pairs[field_key]
if 'type' in metadata.keys():
match metadata['type']:
case 'int' : cell.value = int(value)
case 'float': cell.value = float(value)
case 'money': cell.value = float(value)
case 'date' : cell.value = \
datetime.strptime(value, "%d/%m/%Y")
else: cell.value = valueRun: Write, and Decorate
Writing entries, takes an effort, and a bunch of codelines.
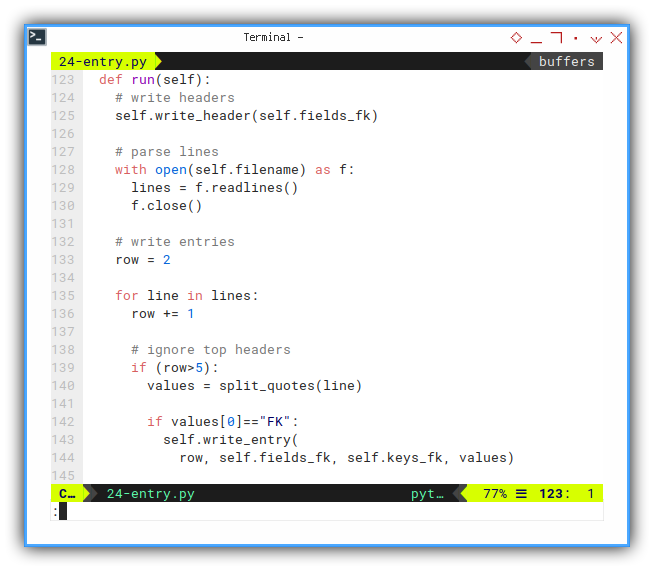
First, read the file.
def run(self):
# write headers
self.write_header(self.fields_fk)
# parse lines
with open(self.filename) as f:
lines = f.readlines()
f.close()Then iterate each lines.
# write entries
row = 2
for line in lines:
row += 1
# ignore top headers
if (row>5):
values = split_quotes(line)
if values[0]=="FK":
self.write_entry(
row, self.fields_fk, self.keys_fk, values)The rest are the same.
Result
We display a few in output, so we know what master filed are processed.
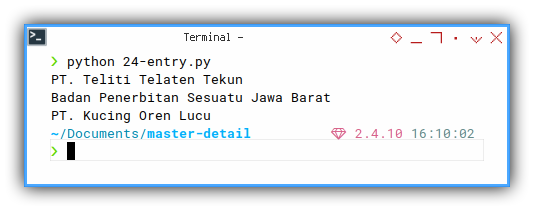
But the real result, are all written in spreadsheet.
Sheet Result
How about the output?
Consider to open the sample.xlsx spreadsheet. This is going to be very wide sheet. So I took three screenshots.
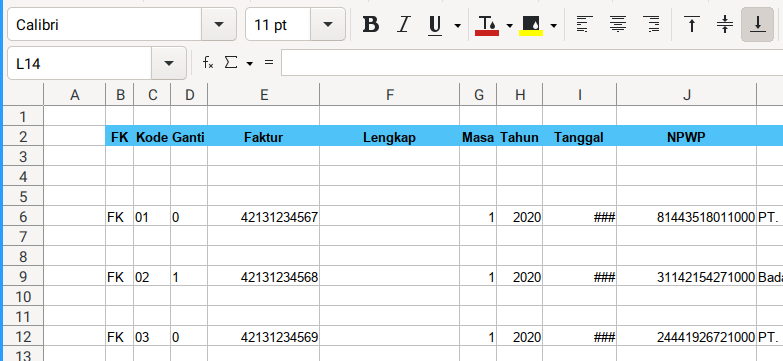
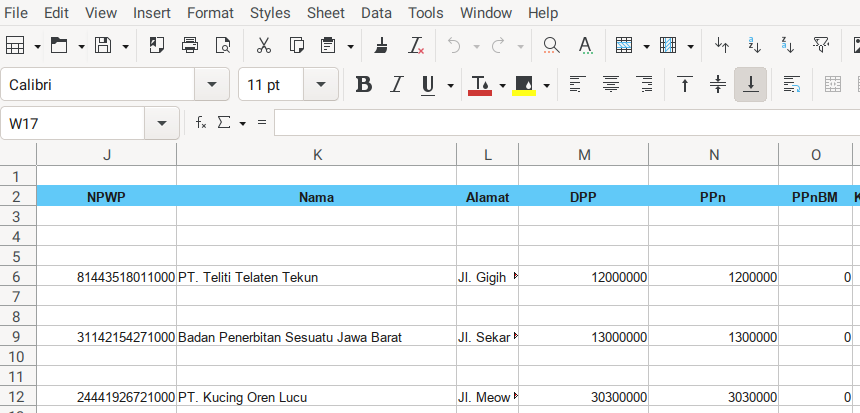
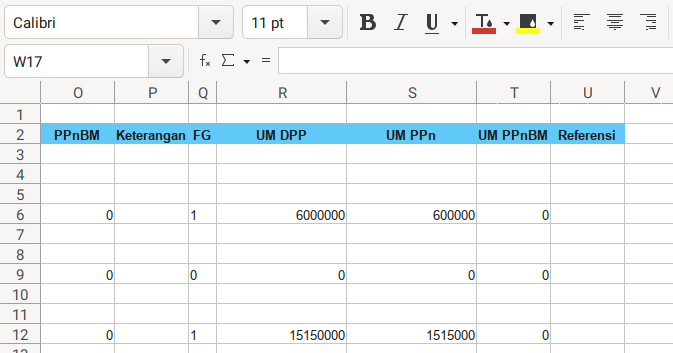
4: Writing Master Detail Entries
Process All Three Kind of Headers, with Formatting
This is the same as previous code, but with details.
Source
Just an OOP version modification of previous code.
Header Keys
Put header name definition in its own function.
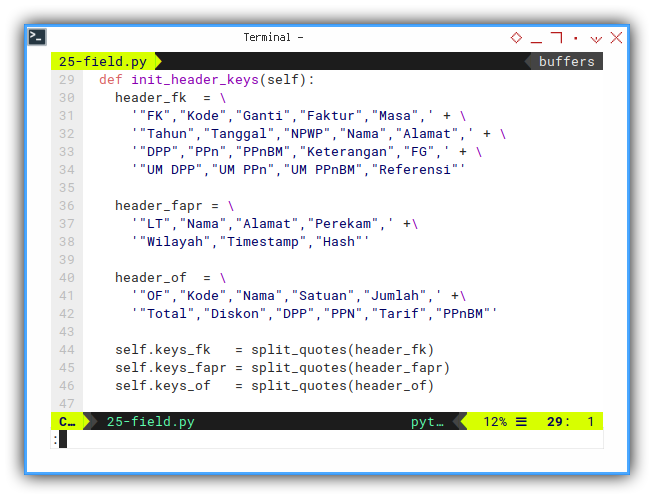
def init_header_keys(self):
header_fk = \
'"FK","Kode","Ganti","Faktur","Masa",' + \
'"Tahun","Tanggal","NPWP","Nama","Alamat",' + \
'"DPP","PPn","PPnBM","Keterangan","FG",' + \
'"UM DPP","UM PPn","UM PPnBM","Referensi"'
header_fapr = \
'"LT","Nama","Alamat","Perekam",' +\
'"Wilayah","Timestamp","Hash"'
header_of = \
'"OF","Kode","Nama","Satuan","Jumlah",' +\
'"Total","Diskon","DPP","PPN","Tarif","PPnBM"'
self.keys_fk = split_quotes(header_fk)
self.keys_fapr = split_quotes(header_fapr)
self.keys_of = split_quotes(header_of)And extract.
Field Metadata
Add some cool format.
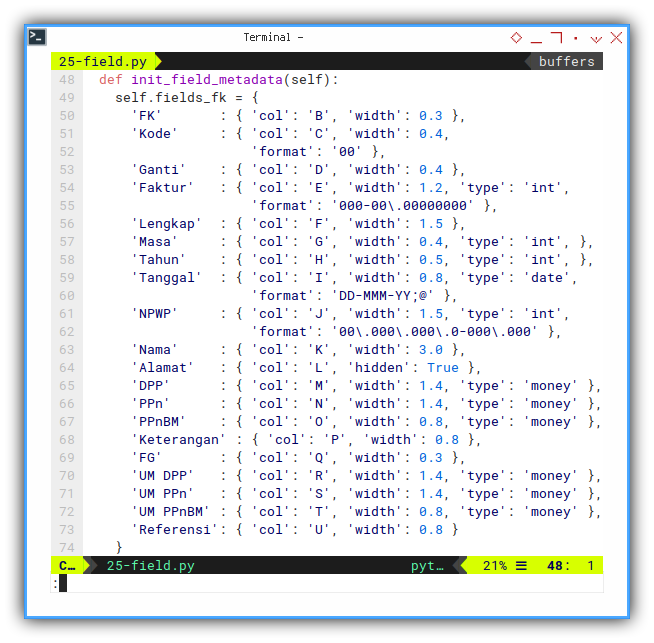
def init_field_metadata(self):
self.fields_fk = {
'FK' : { 'col': 'B', 'width': 0.3 },
'Kode' : { 'col': 'C', 'width': 0.4 },
'Ganti' : { 'col': 'D', 'width': 0.4 },
'Faktur' : { 'col': 'E', 'width': 1.2, 'type': 'int' },
'Lengkap' : { 'col': 'F', 'width': 1.5 },
'Masa' : { 'col': 'G', 'width': 0.4, 'type': 'int', },
'Tahun' : { 'col': 'H', 'width': 0.5, 'type': 'int', },
'Tanggal' : { 'col': 'I', 'width': 0.8, 'type': 'date',
'format': 'DD-MMM-YY;@' },
'NPWP' : { 'col': 'J', 'width': 1.5, 'type': 'int' },
'Nama' : { 'col': 'K', 'width': 3.0 },
'Alamat' : { 'col': 'L', 'hidden': True },
'DPP' : { 'col': 'M', 'width': 1.4, 'type': 'money' },
'PPn' : { 'col': 'N', 'width': 1.4, 'type': 'money' },
'PPnBM' : { 'col': 'O', 'width': 0.8, 'type': 'money' },
'Keterangan' : { 'col': 'P', 'width': 0.8 },
'FG' : { 'col': 'Q', 'width': 0.3 },
'UM DPP' : { 'col': 'R', 'width': 1.4, 'type': 'money' },
'UM PPn' : { 'col': 'S', 'width': 1.4, 'type': 'money' },
'UM PPnBM' : { 'col': 'T', 'width': 0.8, 'type': 'money' },
'Referensi': { 'col': 'U', 'width': 0.8 }
}And also complete field metadata for other row as well.
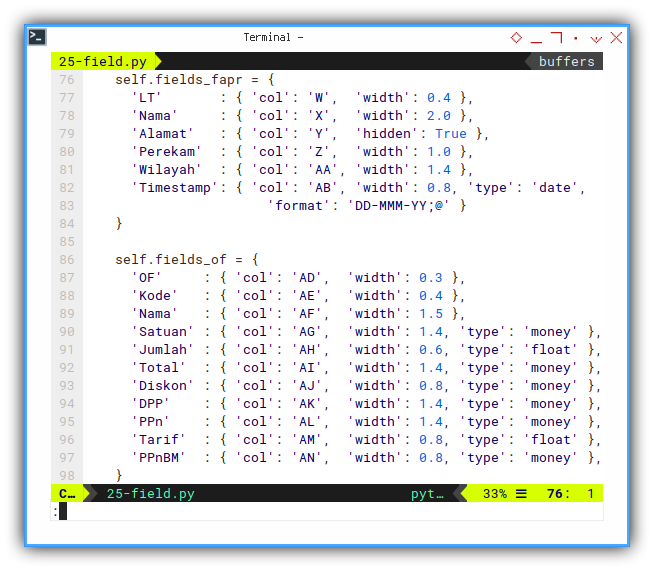
self.fields_fapr = {
'LT' : { 'col': 'W', 'width': 0.4 },
'Nama' : { 'col': 'X', 'width': 2.0 },
'Alamat' : { 'col': 'Y', 'hidden': True },
'Perekam' : { 'col': 'Z', 'width': 1.0 },
'Wilayah' : { 'col': 'AA', 'width': 1.4 },
'Timestamp': { 'col': 'AB', 'width': 0.8, 'type': 'date',
'format': 'DD-MMM-YY;@' }
}and finally
self.fields_of = {
'OF' : { 'col': 'AD', 'width': 0.3 },
'Kode' : { 'col': 'AE', 'width': 0.4 },
'Nama' : { 'col': 'AF', 'width': 1.5 },
'Satuan' : { 'col': 'AG', 'width': 1.4, 'type': 'money' },
'Jumlah' : { 'col': 'AH', 'width': 0.6, 'type': 'float' },
'Total' : { 'col': 'AI', 'width': 1.4, 'type': 'money' },
'Diskon' : { 'col': 'AJ', 'width': 0.8, 'type': 'money' },
'DPP' : { 'col': 'AK', 'width': 1.4, 'type': 'money' },
'PPn' : { 'col': 'AL', 'width': 1.4, 'type': 'money' },
'Tarif' : { 'col': 'AM', 'width': 0.8, 'type': 'float' },
'PPnBM' : { 'col': 'AN', 'width': 0.8, 'type': 'money' },
}Cell Divider
What is not stored in metadata, can also be taken care of.
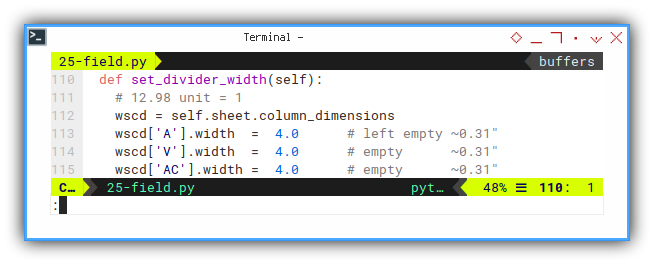
def set_divider_width(self):
# 12.98 unit = 1
wscd = self.sheet.column_dimensions
wscd['A'].width = 4.0 # left empty ~0.31"
wscd['V'].width = 4.0 # empty ~0.31"
wscd['AC'].width = 4.0 # empty ~0.31"Cell Content
Consider go deeper into detail
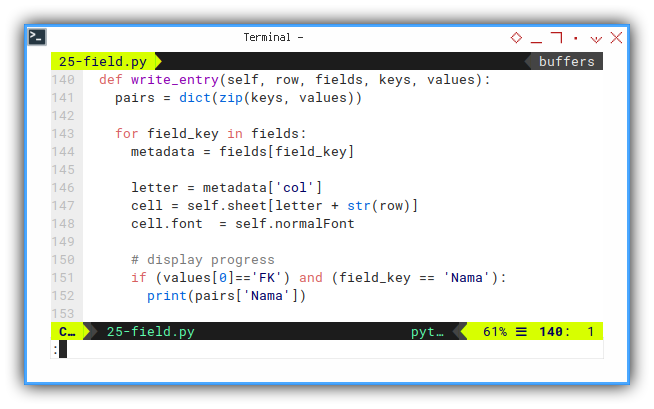
def write_entry(self, row, fields, keys, values):
pairs = dict(zip(keys, values))
for field_key in fields:
metadata = fields[field_key]
letter = metadata['col']
cell = self.sheet[letter + str(row)]
cell.font = self.normalFont
# display progress
if (values[0]=='FK') and (field_key == 'Nama'):
print(pairs['Nama'])And take care of the value.
I know it is a little bit messy here, since we use field name, mixed with metadata.
# take care of value
if field_key in keys:
value = pairs[field_key]
if 'type' in metadata.keys():
match metadata['type']:
case 'int' : cell.value = int(value)
case 'float': cell.value = float(value)
case 'money': cell.value = float(value)
case 'date' :
if field_key=='Tanggal': cell.value = \
datetime.strptime(value, "%d/%m/%Y")
if field_key=='Timestamp':
if len(value) > 8: cell.value = \
datetime.strptime(value[0:8], "%Y%m%d")
else: cell.value = value
elif field_key=='Lengkap':
faktur = "%013s" % pairs["Faktur"]
faktur = faktur[:3] +'-'+ faktur[3:5] +'.'+ faktur[5:]
cell.value = pairs["Kode"]+pairs["Ganti"]+"."+fakturAnd finally cell formatting:
# take care of format
if 'format' in metadata.keys():
cell.number_format = metadata['format']
elif ('type' in metadata.keys()) \
and (metadata['type']=='money'):
# beware of the comma or period, depend on locale
cell.number_format = '" Rp"* #,##0.00 ;' + \
'"-Rp"* #,##0.00 ;" Rp"* -# ;@ 'Run: Write, and Decorate
Writing entries, takes an effort, and a bunch of codelines.
First, read the file. Write all there kind of headers.
def run(self):
# write headers
self.write_header(self.fields_fk)
self.write_header(self.fields_fapr)
self.write_header(self.fields_of)
self.set_divider_width()
# parse lines
with open(self.filename) as f:
lines = f.readlines()
f.close()Then iterate each lines.
# write entries
row = 5
# ignore top headers
for line in lines[3:]:
row += 1
values = split_quotes(line)
match values[0]:
case "FK" : self.write_entry (
row, self.fields_fk, self.keys_fk, values)
case "FAPR": self.write_entry (
row, self.fields_fapr, self.keys_fapr, values)
case "OF" : self.write_entry (
row, self.fields_of, self.keys_of, values)The rest are the same.
Result
We display a few in output, so we know what master filed are processed.
But the real result, are all written in spreadsheet.
Sheet Result
How about the output?
Consider to open the sample.xlsx spreadsheet.
- Output: sample.xlsx
This is going to be very wide sheet. So I took five screenshots.
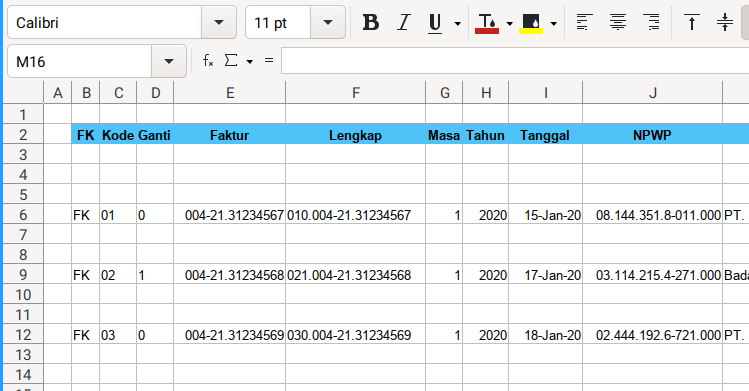
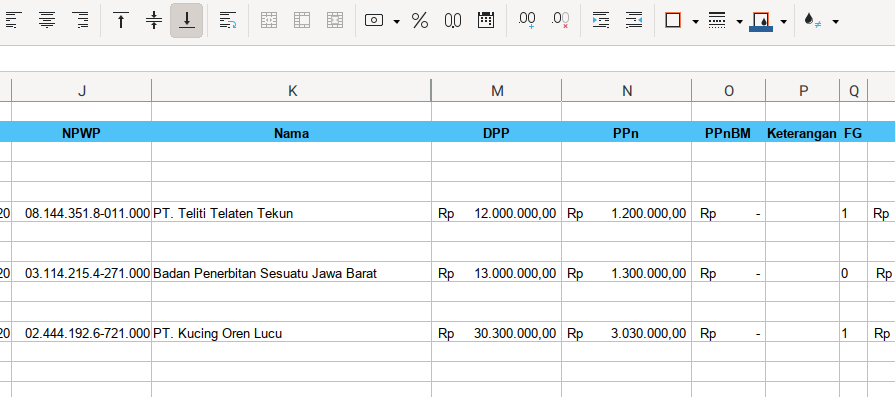
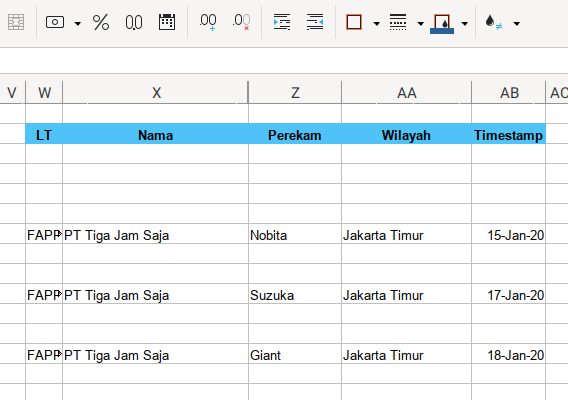
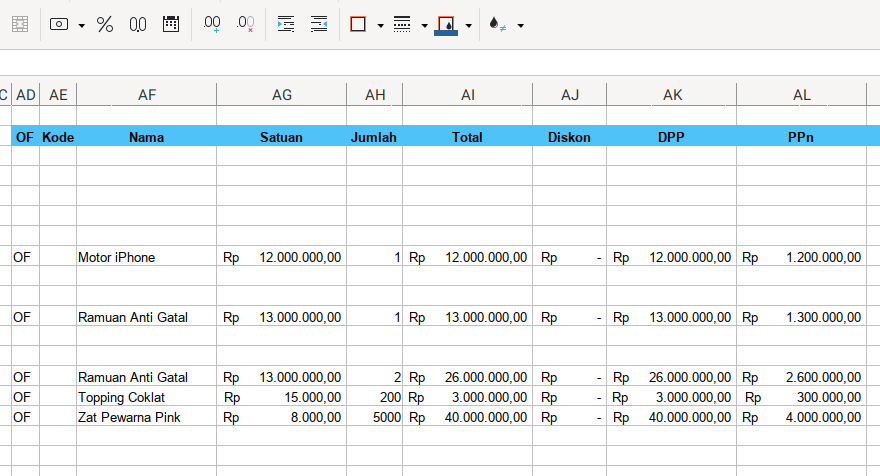
This master detail table is shown clear if we just hide some field.
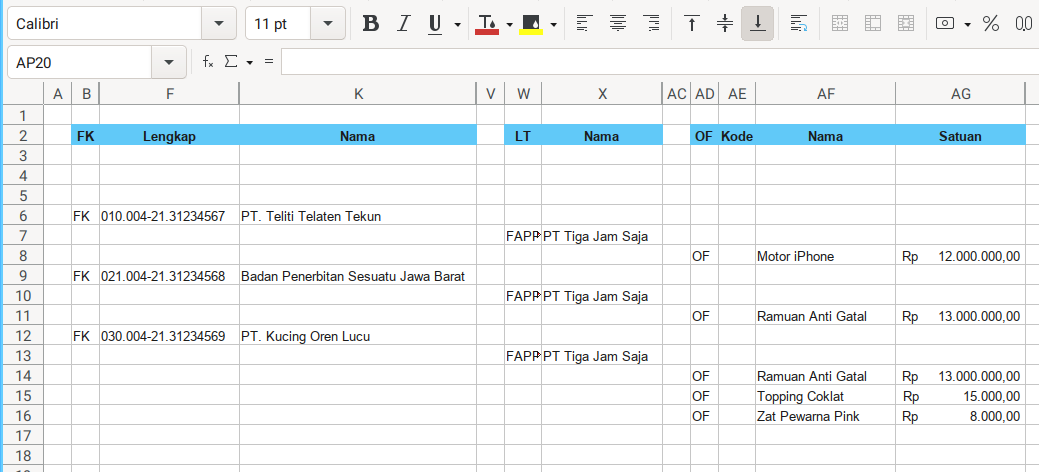
As you can see, now you have master detail table.
Related Article
Optionally, you can read the libreoffice uno part.
What is Next 🤔?
Still about tax, I have a cool trick to transform plain row based data into cute form view.
Consider continue reading [ Python - Excel - Copy Range ].